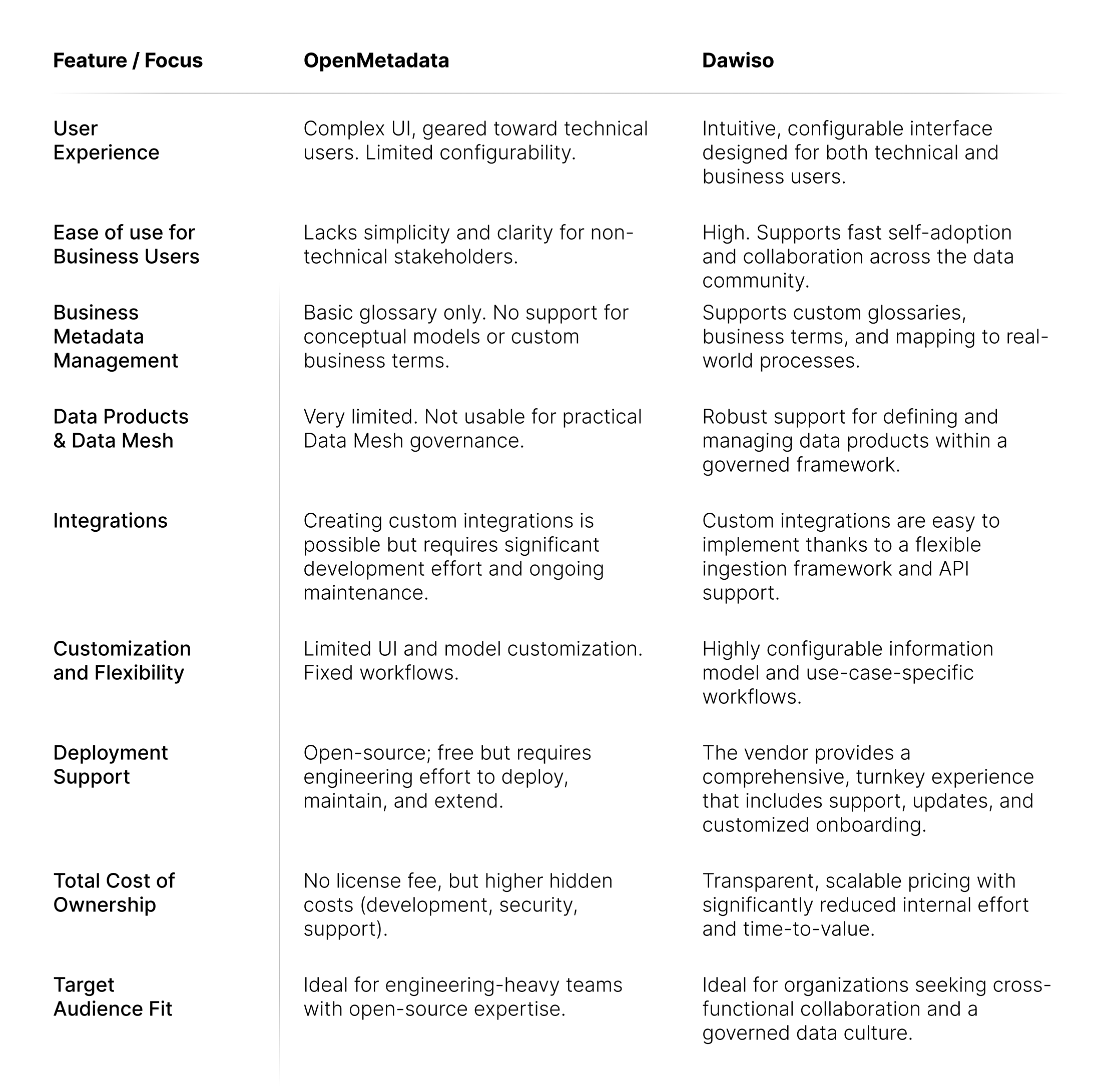
What Are the Differences Between OpenMetadata and Dawiso Data Catalog?

OpenMetadata has become the standard for open-source data governance. With its reasonably easy deployment and low cost, it's often the tool of choice for many smaller teams looking for affordable metadata management. But is it the right one?
This article compares two fundamentally different approaches: OpenMetadata, an open-source, community-driven framework, and Dawiso, a vendor-supported data catalog designed to be intuitive, accessible, and governance-ready out of the box. We’ll explore their strengths, limitations, and how to choose the best fit for your organization, whether you prioritize flexibility and control, or simplicity and long-term support.
OpenMetadata vs. Dawiso: A Practical Comparison
While OpenMetadata has gained popularity as an open-source metadata platform, it comes with several limitations that can make it challenging to use as a full-featured data portal, especially for organizations aiming to involve both technical and business users. Are you considering OpenMetadata and looking for alternatives? Let’s break down the key differences based on usability, metadata capabilities, data product governance, integrations, and overall adaptability.
OpenMetadata strengths and potential benefits
OpenMetadatais a fast-evolving open-source framework for metadata management that has gained traction among data engineering teams. It provides a flexible foundation for building a metadata catalog, but its strengths are primarily technical and come with notable trade-offs.
1. Open-source foundation (Apache 2.0 license)
OpenMetadata is free to use, modify, and distribute. This appeals to organizations that prioritize openness, want to avoid vendor lock-in, or aim to experiment with metadata initiatives without upfront licensing costs.
However, “free” applies only to the software itself, not to the cost of deploying, maintaining, or scaling it. Read the details below.
2. Extensible and developer-friendly architecture
Its modular design and available APIs (REST and GraphQL) allow skilled teams to build custom integrations, pipelines, or even modify the data model.
This flexibility assumes a high level of in-house technical skill. There's no UI-driven configuration layer for non-engineers.
3. Support for technical metadata
OpenMetadata supports ingestion from widely used technical sources like Snowflake, BigQuery, Redshift, dbt, and Kafka. It includes technical lineage extraction, schema versioning, usage statistics, and basic data profiling.
However, while these features exist, they often require hands-on configuration, scripting, and familiarity with the underlying metadata APIs. Compared to commercial catalogs, OpenMetadata offers fewer plug-and-play connectors, limited UI-driven setup, and less depth in business-context enrichment, making it more suitable for engineering teams than mixed business-technical environments.
4. Active open-source community
The platform is in active development with regular GitHub releases and community discussions. Issues are addressed relatively quickly, and contributors can shape the roadmap.
Community-led does not equal enterprise-grade support. There's no SLA or guaranteed help unless you purchase services from a third-party provider.
5. Cloud-native deployment options
Designed for Docker and Kubernetes, OpenMetadata fits well into modern DevOps workflows and supports scalable, containerized environments. Initial setup and ongoing operations still require infrastructure expertise and monitoring resources.
Current limitations of OpenMetadata
Limited usability for business users
OpenMetadata's user interface is built with data engineers in mind. The navigation, diagram views, and customization options are not intuitive for non-technical users. Plus, the customization options are very limited. This can limit adoption among business teams who need quick, simple access to data context without technical training.
Basic business metadata management
The platform offers only a simple business glossary with limited modeling capabilities. There's no native support for conceptual models, business rules, or the ability to map custom business terminology to technical metadata, making it difficult to create a shared understanding of data across departments.
Weak support for data products and Data Mesh
While OpenMetadata includes basic support for data assets, it lacks the governance framework needed to manage data as well-defined, reusable products. This makes it hard to decentralize ownership and deliver data as a reliable product to internal consumers.
Limited support for specialized integrations
OpenMetadata supports many common data sources through built-in connectors, but most of them require hands-on setup and configuration rather than offering plug-and-play convenience. This can increase complexity and time-to-value, especially for teams with limited engineering resources. Additionally, integrations with platforms like Keboola or GoodData are not available out of the box and would need to be custom-developed, further adding to implementation effort and ongoing maintenance.
Hidden Costs: Open Source vs. Vendor Data Catalogs
Open-source software may appear free at first, but a deeper investigation often uncovers substantial hidden costs.
1. Development and customization
Open-source catalogs like OpenMetadata require internal or outsourced engineering effort for deployment, integrating systems, and building custom connectors. Roll-your-own deployment can easily cost 2–3× more in personnel time than adopting a commercial product, even after factoring in licensing fees.
2. Ongoing maintenance and support
Community-driven updates and bug fixes lack SLA guarantees. You’ll need dedicated engineers for patches, security updates, and version upgrades, often full-time for larger deployments.
3. Security, governance, and compliance
Unlike vendor solutions that include hardened security, open-source tools depend on your team or community to proactively manage vulnerabilities, licensing changes, and audit-readiness.
4. Feature gaps and piecemeal integrations
Commercial catalogs package enterprise-grade connectors, UI polish, AI-powered automation, and governance controls together. Open-source alternatives often lack these out-of-the-box features, meaning more in-house development or add-on tooling.
While OpenMetadata doesn’t carry licensing fees, the total engineering effort required for setup, customization, and maintenance can result in six-figure annual costs, even in European mid-sized organizations.
Dawiso’s strengths and potential benefits
1. User-friendly data portal
Dawiso is designed for wide adoption across the data community (from data engineers to business analysts). Its intuitive interface supports configurable views and diagrams, making it easy for all users to navigate, understand, and contribute to metadata. So, we can say Dawiso is a data catalog for business users.
2. Comprehensive business metadata management
Dawiso offers a flexible metadata model that supports custom business glossaries, conceptual models, and business-to-technical mapping. This enables consistent interpretation of data and strengthens collaboration between business and IT. Customizability options are at the highest level across all vendors.
3. Robust data product and Data Mesh support
With dedicated features for defining, describing, and governing data products, Dawiso helps organizations embrace modern data architecture approaches. It allows teams to publish, manage, and track data products efficiently within a governed framework.
4. Built-in integrations and flexibility
Dawiso provides a wide range of plug-and-play connectors that make it easy to integrate with modern data platforms, without the need for complex setup or custom development. This allows teams to onboard quickly and focus on value instead of configuration. It also supports custom ingestion scenarios and metadata synchronization with other catalogs for advanced use cases.
Platforms like Keboola, GoodData, and many others are supported natively.
See the full list of available integrations.
5. Cloud-native and easy to deploy
Dawiso is built on a modern, cloud-based architecture. It can be deployed in Dawiso's managed cloud or within the customer’s own Azure or AWS environment. Setup is fast, with minimal configuration needed, allowing teams to start cataloging data within hours, not weeks. More about deployment in this article.
6. Regular product updates
As a vendor-supported solution, Dawiso benefits from an active development roadmap. New features, usability enhancements, and integration updates are released regularly based on user feedback and evolving data governance trends. These updates are automatically deployed, ensuring that each customer’s environment stays up to date without requiring manual intervention or additional effort.
7. Reliable customer support
Dawiso offers responsive customer support tailored to each client’s needs. From onboarding guidance to troubleshooting and expert advice, our team ensures that organizations aren’t left on their own when deploying or scaling their data catalog. In addition to technical support, we also help clients define governance structures, ownership models, and data product frameworks to ensure the platform fits their business context and drives real value.
Dawiso Limitations
Commercial licensing model
While Dawiso is priced affordably for many mid-sized organizations, it still involves a license fee. For startups or teams with no budget for commercial software, this could be a barrier when compared to free open-source tools (despite the latter’s hidden costs).
Optimized for usability, not DIY development
Dawiso is designed to be user-friendly and highly configurable through its interface and metadata model, making it accessible across the organization. While it offers extensive customization options, it is not a platform intended for low-level scripting or code-based extension by in-house developers. Teams looking to fully build their own tooling from the ground up may prefer an open-source framework like OpenMetadata.
Choosing the right data catalog can make or break your data governance strategy. As organizations face growing pressure to ensure data quality, traceability, and compliance, the role of the data catalog has evolved from a nice-to-have to a foundational tool for managing enterprise data. But with so many solutions on the market, ranging from open-source frameworks like OpenMetadata to vendor-supported platforms like Dawiso, it could be difficult to make the right choice.
Choosing your data catalog is a long-term commitment
The decision isn’t trivial. Implementing a data catalog requires significant alignment across teams, and once adopted, it becomes deeply embedded in both technical and business workflows. Replacing it later is far more complex than it may initially seem. That’s why it’s crucial to understand what matters most when evaluating your options: usability, scalability, ease of deployment, automation capabilities, governance features, and support for your data ecosystem.
How to Choose the Best Data Catalog Tool for Your Organization
Choosing a data catalog isn’t just about ticking boxes on a feature list. It’s about finding a solution that supports your data strategy, matches your team’s maturity level, and fits into your existing ecosystem. Here are some of the most important aspects to consider:
Ease of use
A data catalog should be accessible not just for data engineers. Look for a user interface that makes it easy for both technical and business users to find, understand, and contribute to metadata. The more intuitive the platform is, the higher the adoption rate across teams will be, leading to better data democratization.
Customization
Every industry and every organization has its own terminology, processes, and structures. A flexible data catalog allows you to tailor metadata models, user roles, and workflows to reflect how your teams actually work, rather than forcing you to adapt to the tool.
Data governance and compliance features
As regulatory expectations rise, your catalog should do more than just organize metadata. It should support governance workflows, ownership models, access controls, and audit trails. These features help ensure your data assets remain trustworthy and compliant over time.
Automation and AI capabilities
Manually documenting and maintaining metadata is time-consuming and prone to errors, with much of the work in data governance still being done manually. Like tagging objects, updating statuses, and assigning owners. It’s time-consuming, repetitive, and often unrealistic to expect teams to do it all by hand. Platforms that use automation and AI can significantly reduce this burden by auto-discovering metadata, auto-tagging, automated customized workflows, and suggesting relationships, saving your team time while improving accuracy.
Built-in integrations
A modern catalog should connect seamlessly with the tools in your data stack. ETL platforms, data warehouses, BI tools, and more. Strong native integrations mean smoother implementation, faster time to value, and less maintenance effort.

Scalable pricing
As your data footprint grows, so does your need for comprehensive metadata management. Choose a catalog with transparent, scalable pricing that won’t become a blocker as your needs evolve. This is especially critical for smaller teams or fast-growing organizations. Dawiso pricing is available here.
With vendor-supported tools, pricing usually depends on usage, users, or features, and includes access to support, updates, and service-level guarantees. In contrast, open-source tools like OpenMetadata are technically free to use, but that doesn’t mean they’re cost-free. You’ll likely need internal resources or external consultants to deploy, configure, maintain, and secure the system. While this can be appealing for organizations with strong in-house engineering capabilities, others may find that vendor-provided solutions offer a more predictable and cost-effective total cost of ownership in the long run.
Comprehensive customer support
Even the best tools come with a learning curve. Vendor support, documentation quality, and access to a responsive help desk or community can make a major difference in how successful your implementation is and how fast your team can get value from the catalog.
Summary
While OpenMetadata is a solid choice for teams with strong technical capabilities and a preference for open-source, it may fall short for organizations looking to engage business users, manage data products, and build a comprehensive data portal with minimal engineering overhead.
For those without internal engineering capacity or the appetite to build and maintain their own metadata layer, a vendor-supported platform may offer a more sustainable and business-aligned path.
Dawiso offers a more accessible, governance-ready alternative that enables organizations to scale their metadata practices across the enterprise, supporting transparency, ownership, and trust in data.
If you're interested in comparing other catalogs, check out our Data Catalogs Comparison Guide.
Frequently Asked Questions
What is the difference between OpenMetadata and Dawiso?
OpenMetadata is an open-source, developer-focused metadata platform, while Dawiso is a vendor-supported, business-friendly data catalog with strong governance and integration features.
Is OpenMetadata free to use?
Open-source tools like OpenMetadata are technically free to use, but that doesn’t mean they’re cost-free. So, yes, but only the software. Costs arise from deployment, customization, and long-term maintenance.
Is Dawiso suitable for small or mid-sized companies?
Yes. Dawiso offers scalable pricing, easy deployment, and intuitive features that make it a strong fit for mid-sized teams looking to improve data governance.
Can Dawiso replace OpenMetadata in enterprise use cases?
Yes. Dawiso includes features for both business and technical users, robust integration options, and support for data products, areas where OpenMetadata may require heavy custom development.


