Why Robust Data Governance Is Essential for Unstructured Data

Managing unstructured data at scale is one of the biggest challenges in many enterprises. The public discourse surrounding this important topic is limited, which leaves many organizations confused by the complexities of unstructured data. Today, as we enter a new era of Generative AI, the need to address these challenges has never been more urgent.
Once tolerated as an opaque byproduct of business operations, it’s now at the center of how we communicate, make decisions, and train AI models. Internal procedures, SOPs, reports, presentations, recordings, chat logs, screenshots, and scanned documents make up a huge amount of enterprise data. Yet most of it remains unmanaged, ungoverned, and invisible to enterprise data systems.
That’s a risk and a missed opportunity. Governing unstructured data is the foundation for using this data safely, effectively, and in ways that scale across your organization and your AI initiatives.
Why is unstructured data difficult to govern?
Unstructured data lacks a predefined schema. Its meaning is contextual, scattered across paragraphs or pages.
Common issues include poor visibility, documents are stored in disconnected systems, drives, SharePoint, inboxes, without traceability. Metadata is not standardized, which means the files often lack descriptions, tags, ownership, or links to business definitions. Sensitive information (e.g., PII, outdated contracts) may go unnoticed and unprotected.
And yet, this data is being pulled into enterprise workflows, especially in AI projects, without sufficient context, quality checks, or explainability. That’s a governance problem.
How to govern unstructured data?
As mentioned, unlike structured data, you can’t rely on pre-built schemas or data models to govern unstructured content. Instead, governance must focus on metadata, ownership, and context.
A robust unstructured data governance approach should include:
1. Metadata enrichment
Automatically or manually assign categories, tags, and descriptions.
2. Ownership and accountability
Define who manages the content and who can access or update it.
3. Lineage and versioning
Track when documents were created or changed, and why.
4. Linkage to structured concepts
Connect unstructured content to KPIs, business glossary terms, or data domains.
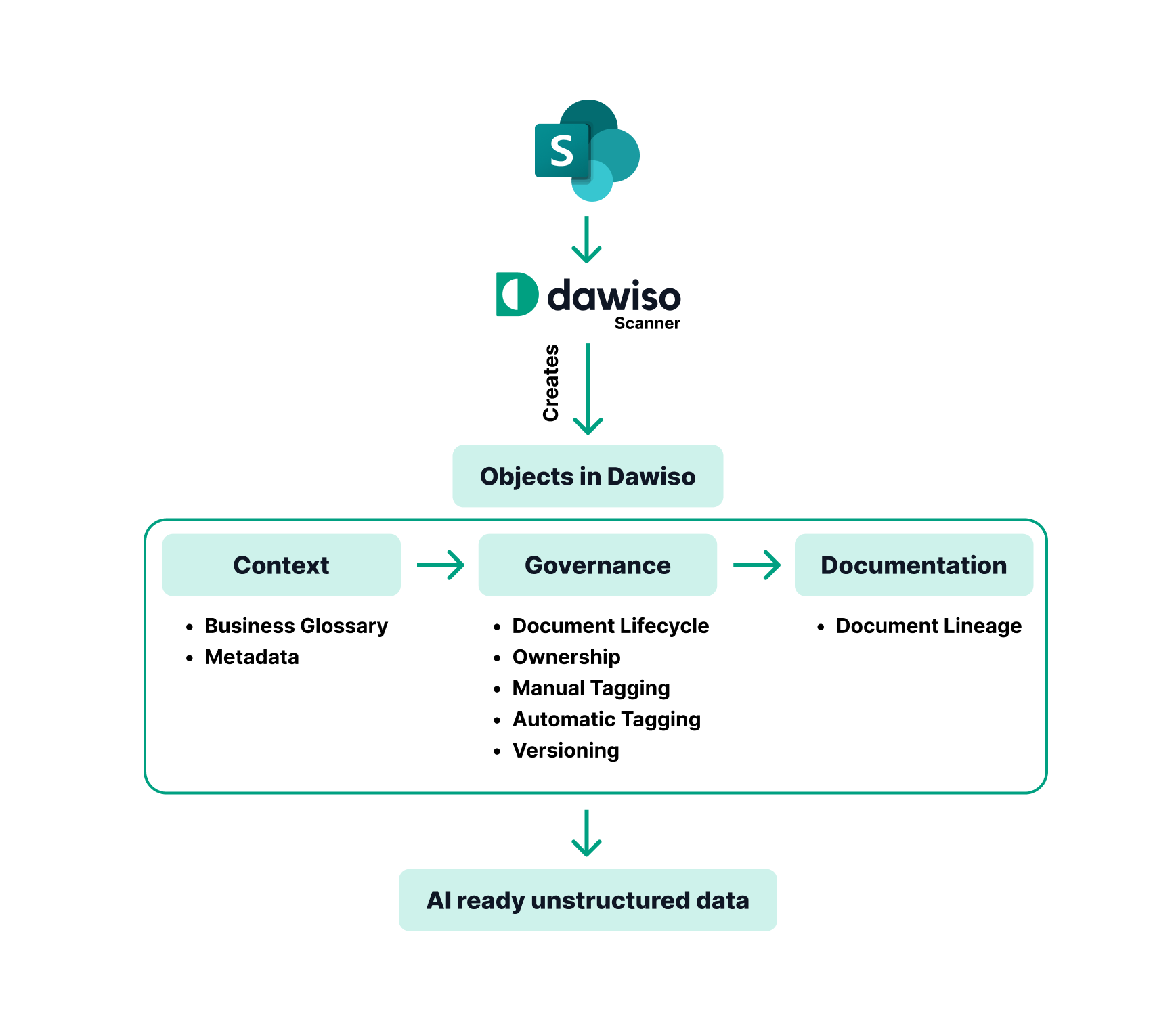
A layered model for unstructured data governance
Let’s take inspiration from frameworks like the Medallion Architecture, originally designed for structured data pipelines, and apply a similar layered governance model to unstructured content. This approach helps teams organize data across different levels of usability and quality.
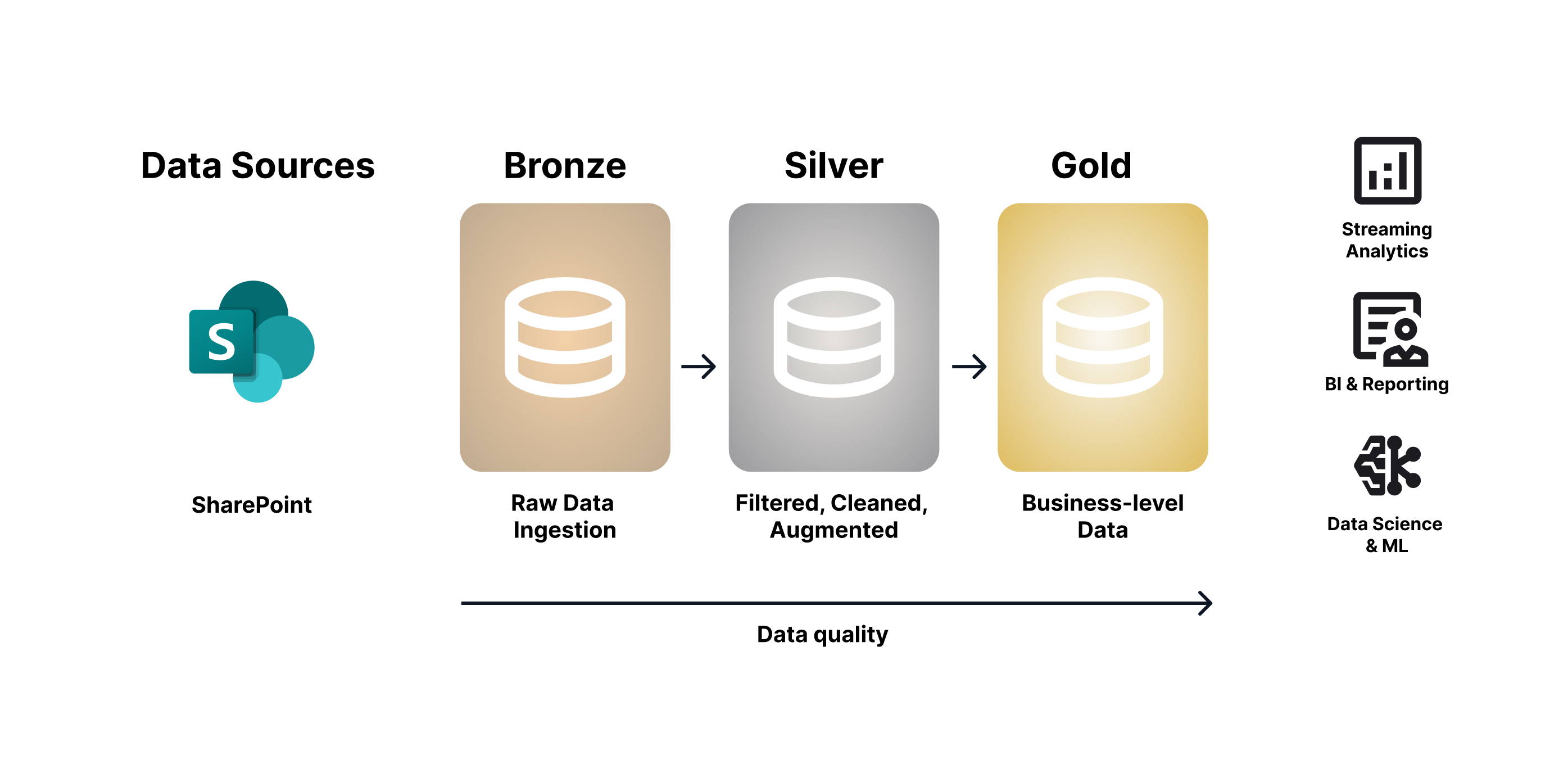
1. Bronze Layer – Raw Storage
- Ingest documents and files in their original state.
- Capture basic metadata like source system, creation date, and responsible team.
- Store with minimal processing but clear ownership.
2. Silver Layer – Structuring and Linking
- Enrich content with extracted entities, categories, and glossary links.
- Use Dawiso's autolinking and AI summarization features to create meaningful connections.
- Standardize naming conventions and validate metadata quality.
3. Gold Layer – Curated, Searchable, AI-Ready
- Make content discoverable across business units through governance portals.
- Support retrieval-augmented generation (RAG) by LLMs using curated, trusted documents.
- Embed unstructured data into dashboards, workflows, and compliance reporting.
Retrieval-Augmented Generation
One of the most powerful ways to get value from unstructured content today is through Retrieval-Augmented Generation (RAG), a framework that enhances large language model (LLM) outputs by injecting real-time, external knowledge into the response process.
In practical terms, this means AI is no longer confined to static, pre-trained information. With RAG, it can retrieve relevant, up-to-date content, such as internal documentation, reports, policies, or knowledge base articles, at the time of a query. The model uses this retrieved context to produce responses that are not only more relevant, but also traceable to specific data sources.
To enable this, the process starts by gathering unstructured documents relevant to a particular use case. These documents are then broken into smaller, manageable chunks. Each chunk is converted into a vector embedding, a numerical format that captures the semantic meaning of the text. All these embeddings are stored in a vector database, where similar content is positioned closely based on their meaning.
When someone submits a prompt, the system searches this vector database to retrieve the most relevant chunks. These are then passed, along with the prompt, to the language model, enriching the model’s understanding and enabling it to provide more accurate and context-aware answers.
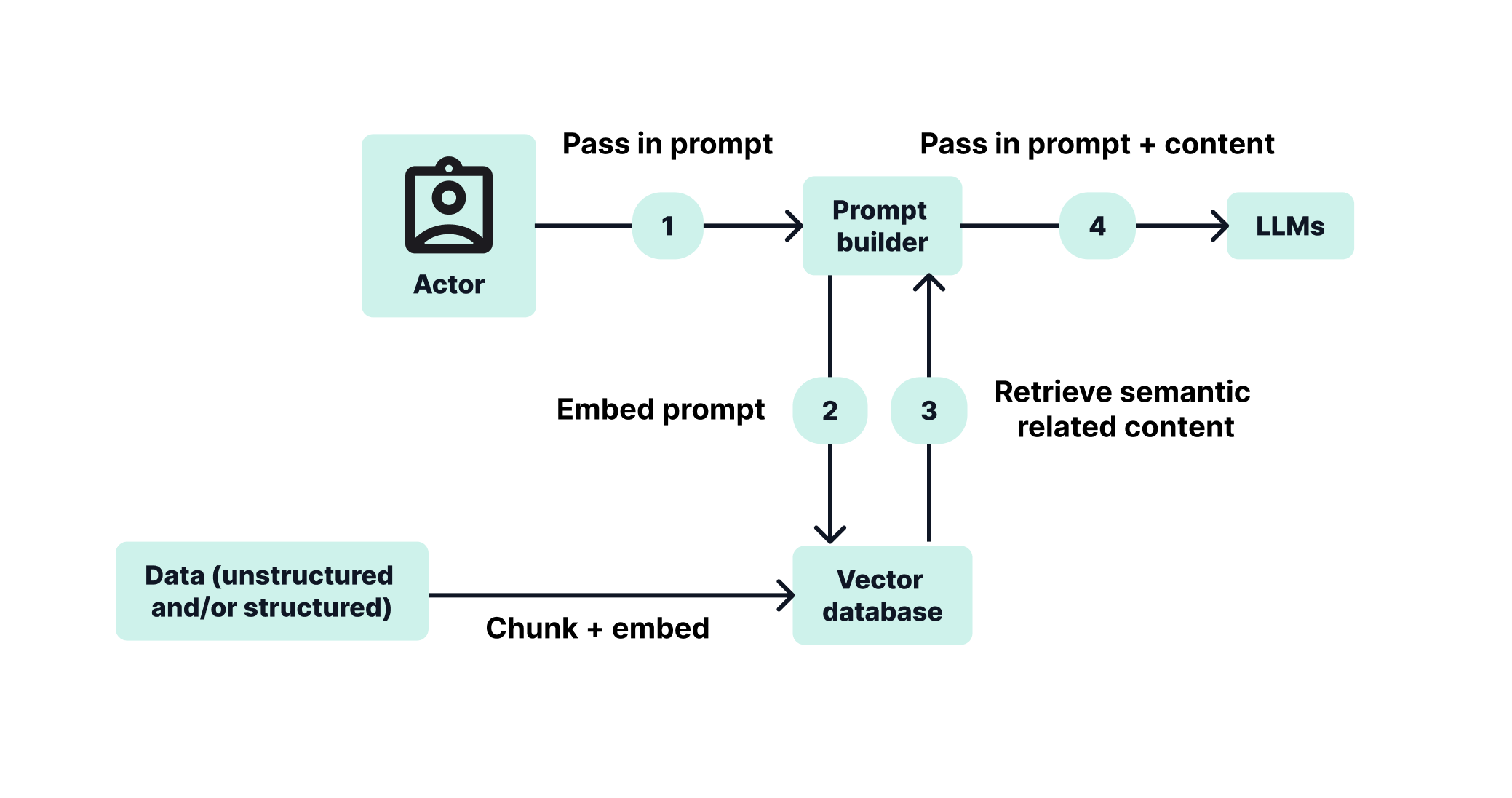
This entire workflow depends on having well-governed, reliable source content. If your documentation is outdated, inconsistent, or poorly labeled, you risk generating flawed or misleading outputs. And when that content includes sensitive data, such as financial policies, legal agreements, or compliance guidance, the cost of inaccuracy becomes even higher.
Now you see exactly where Dawiso plays a crucial role. By embedding governance into the lifecycle of unstructured content, assigning ownership, standardizing terminology, and ensuring consistency, Dawiso ensures that the documents feeding into your AI systems are not only discoverable but trustworthy. It turns unstructured data into an auditable, contextual asset that supports retrieval-based AI safely and transparently.
Governance as the foundation of trustworthy unstructured data
Treating unstructured content as a first-class data asset means applying the same governance discipline you’d expect from any mission-critical dataset.
In the Bronze layer, governance starts early, during ingestion. As documents enter your system, through document management platforms, it’s essential to apply labels, metadata, and ownership markers immediately. This is where Dawiso helps automate classification and ownership assignment, ensuring that even raw, untouched files are never unmanaged. If there are ingestion issues or inconsistent formats, quick feedback loops with the originating teams (like the source application or compliance teams) are crucial to maintain integrity.
Security and sensitivity also begin here. Applying predefined sensitivity labels and classification schemas ensures consistent protection of personal data or confidential business documents across your architecture. Encryption at this stage is optional, but labeling isn’t. Without a clear starting point, it’s impossible to scale safe AI-driven reuse later on.
As data transitions to the Silver layer, the focus shifts toward usability and consistency. This is where Dawiso’s strengths in metadata enrichment, glossary integration, and auto-linking become crucial. Documents can be standardized using defined formats, naming conventions, and domain-specific tags, linking them to structured concepts such as key performance indicators (KPIs) or business processes. These connections organize the content and create intelligent links between related information. As a result, teams can maintain domain-specific control without creating silos.
The Silver layer is where compliance efforts become more refined. Regular reviews of metadata, audits, and validation of document quality help ensure the integrity of your unstructured assets. If a document supports a dashboard metric or is referenced in a policy, it must be current and traceable. At this stage, Dawiso enables teams to start publication workflows or formal sign-offs, preparing governed assets for broader use.
In the Gold layer, governance ensures that content is retrievable, explainable, and ready for AI applications. At this stage, the content is curated, searchable, and optimized for tools like Retrieval-Augmented Generation (RAG). Documents may be semantically chunked, embedded in a vector store, and linked to semantic metadata that enables natural language querying. However, without clearly defined relationships between content and context, such as ownership, business significance, and usage rules, these advanced capabilities can fail to function effectively.
Dawiso acts as the connective tissue here. Its catalog maintains relationships between documents, business terms, data products, and users, ensuring that what gets retrieved by AI isn’t just relevant, but safe, up-to-date, and understandable.
The evolving roles behind unstructured data governance
As organizations scale their governance efforts across structured and unstructured content, new roles are emerging to meet the complexity.
- Data Owners remain responsible for quality and accountability, including unstructured content that supports key business processes.
- Context Engineers take on the critical task of adding meaning, enriching documents with relevant metadata, glossary terms, and business context so they can be reused and interpreted correctly.
- Value Engineers bridge the gap between governance and AI value delivery by focusing on how governed unstructured data integrates into intelligent systems and analytics to create business impact. With the emergence of context-aware protocols like the Model Context Protocol (MCP), there is a growing need for professionals who understand business processes and context. These engineers will refine content, add context, and map complex business scenarios to enable effective agent operations.
- Prompt Engineers are now essential in AI-integrated environments. As context-aware protocols like the Model Context Protocol (MCP) mature, these engineers craft, optimize, and maintain the interactions between data, users, and LLM agents. They translate business needs into precise prompts, select relevant sources, and orchestrate how information flows between knowledge layers and generative tools.
Together, these roles represent a broader cultural shift: treating context and trust as shared responsibilities, not afterthoughts.


