How to Implement an Enterprise Context Layer for AI: A Step-by-Step Guide

A context layer is what gives AI the governed business meaning it needs to use your data correctly. Building one sounds like a multi-quarter infrastructure project, and from scratch it is. With the right foundation it is a sequence of well-understood steps you can complete in weeks. Here is that sequence, step by step, from catalog to MCP delivery to keeping the layer alive.
What a Context Layer Is (and What It Solves)
An AI tool can only be as good as what it understands about your business. A model can read a table, but it cannot know on its own that "active customer" excludes churned trials, that a revenue column is reported net of refunds, or that one of two similarly named datasets is the approved source. A context layer is the governed layer that supplies exactly that: the business meaning, relationships, trust signals, and access rules an AI needs to use your data correctly.
It is worth being precise about how this differs from a semantic layer. A semantic layer translates technical data into business language, so AI knows what your terms mean. A context layer includes that and adds lineage, governance, and provenance on top, then serves the whole thing to AI tools through a standard connection. The semantic layer is one floor; the context layer is the whole building, including the part that makes answers trustworthy and the part that delivers them. This guide walks through building it as six steps.
Step 1: Build the Foundation with a Catalog
You cannot govern context for data you cannot see. The first step is a data catalog that inventories what data assets exist across your landscape, where they live, and how they relate. Connect your sources, warehouses, lakehouses, BI tools, and operational systems, and let the catalog crawl them into a single, searchable inventory.
The output of this step is coverage: a complete picture of the tables, columns, reports, and datasets an AI might be asked about. This is the layer everything else attaches to. Meaning, trust, and policy all hang off catalog entries, so an incomplete catalog produces a context layer with blind spots, the places where AI quietly falls back to guessing. Aim for breadth first; you will deepen specific assets in the steps that follow.
Step 2: Add Meaning with a Glossary
A catalog tells AI what exists. A business glossary tells it what those things mean. This is where you define your metrics and entities once, authoritatively: what "active user," "net revenue," or "qualified lead" actually denotes in your business, including the edge cases that trip up every new analyst.
Link each definition to the catalog assets that implement it, so the meaning and the data are connected rather than living in separate documents. This is the semantic core of the context layer, and it is the single highest-leverage step: a model that knows your definitions interprets retrieved data correctly, and one that does not will confidently report the wrong number. Definitions should be authored by the people who own them, domain experts and stewards, not improvised by whoever wrote the prompt.
"A metric defined in one governed place is worth more than the same metric defined ten times across ten tools."
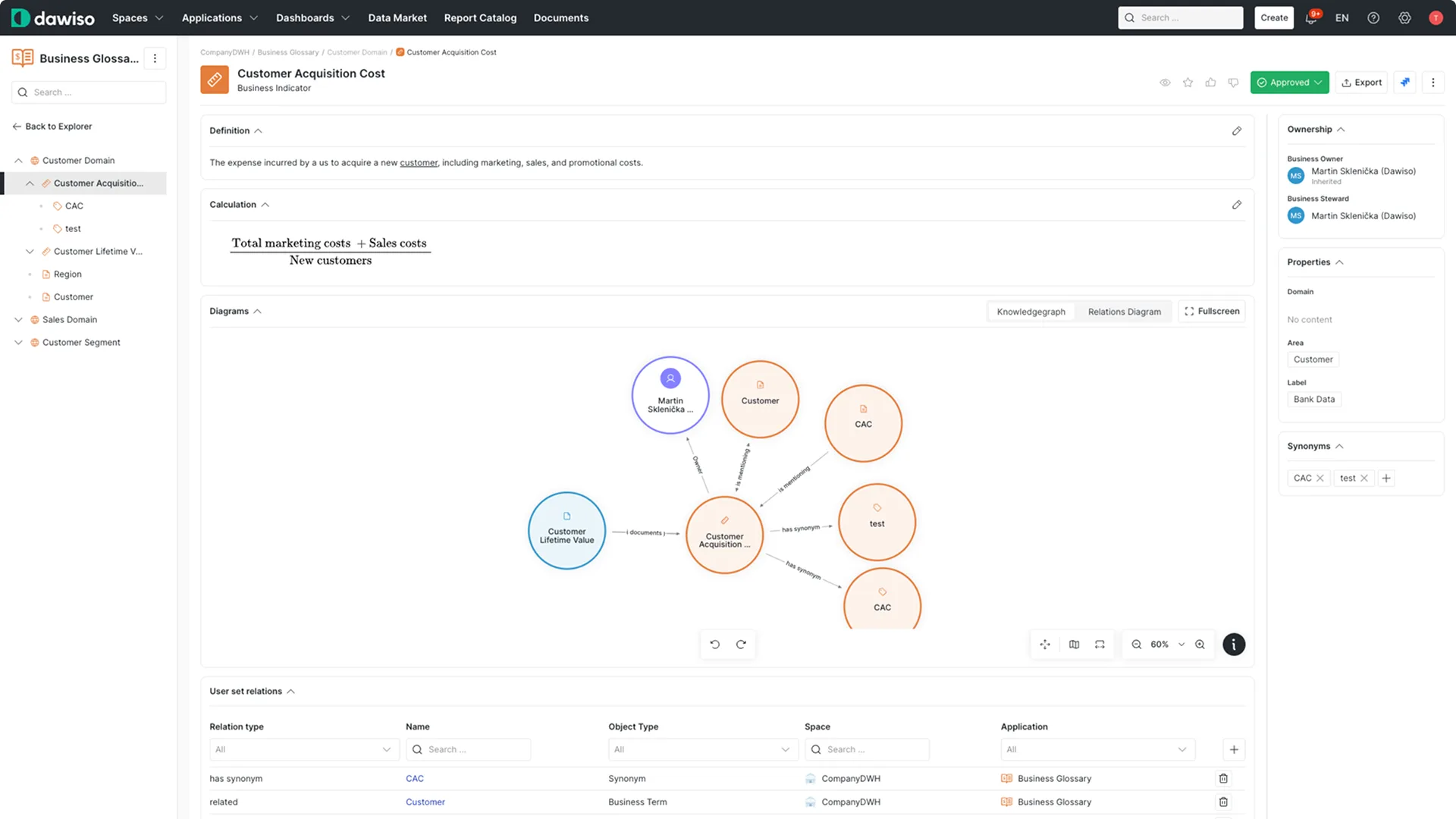
Step 3: Establish Trust with Lineage
Knowing what data means is not the same as knowing whether to trust it. Step three adds data lineage: a traceable map of where each asset came from, what transformed it, and what depends on it. Lineage is what lets an AI answer be traced back to a source, and it is what lets you see, before a problem reaches the model, that a definition is fed by a pipeline that broke last night.
Pair lineage with basic quality signals, freshness, completeness, and whether an asset is certified or deprecated, so the context layer can tell the difference between an authoritative source and a stale copy. Lineage turns "we think the data is fine" into something an AI and an auditor can both verify. In the agent era this is not a nicety: an agent acting on an untraceable number is a compliance and operational risk, not just a wrong dashboard.
Step 4: Attach Policy and Classification
An AI tool that understands your data also needs to know what it is allowed to do with it. Step four attaches classification and access policy to the catalog: which fields contain PII or other sensitive data, how it must be handled, and who, or which agent, may see it.
This is the layer that keeps AI compliant under regimes like the GDPR and the EU AI Act. Without it, a capable assistant can surface a salary table or a customer's personal data to anyone who asks the right question. With it, sensitive context is governed at the source, so the policy travels with the data into every tool that consumes it rather than being re-implemented, inconsistently, inside each one. Classification authored once, here, is what makes "the model decided" an answer you never have to give a regulator.
Step 5: Deliver Context over MCP
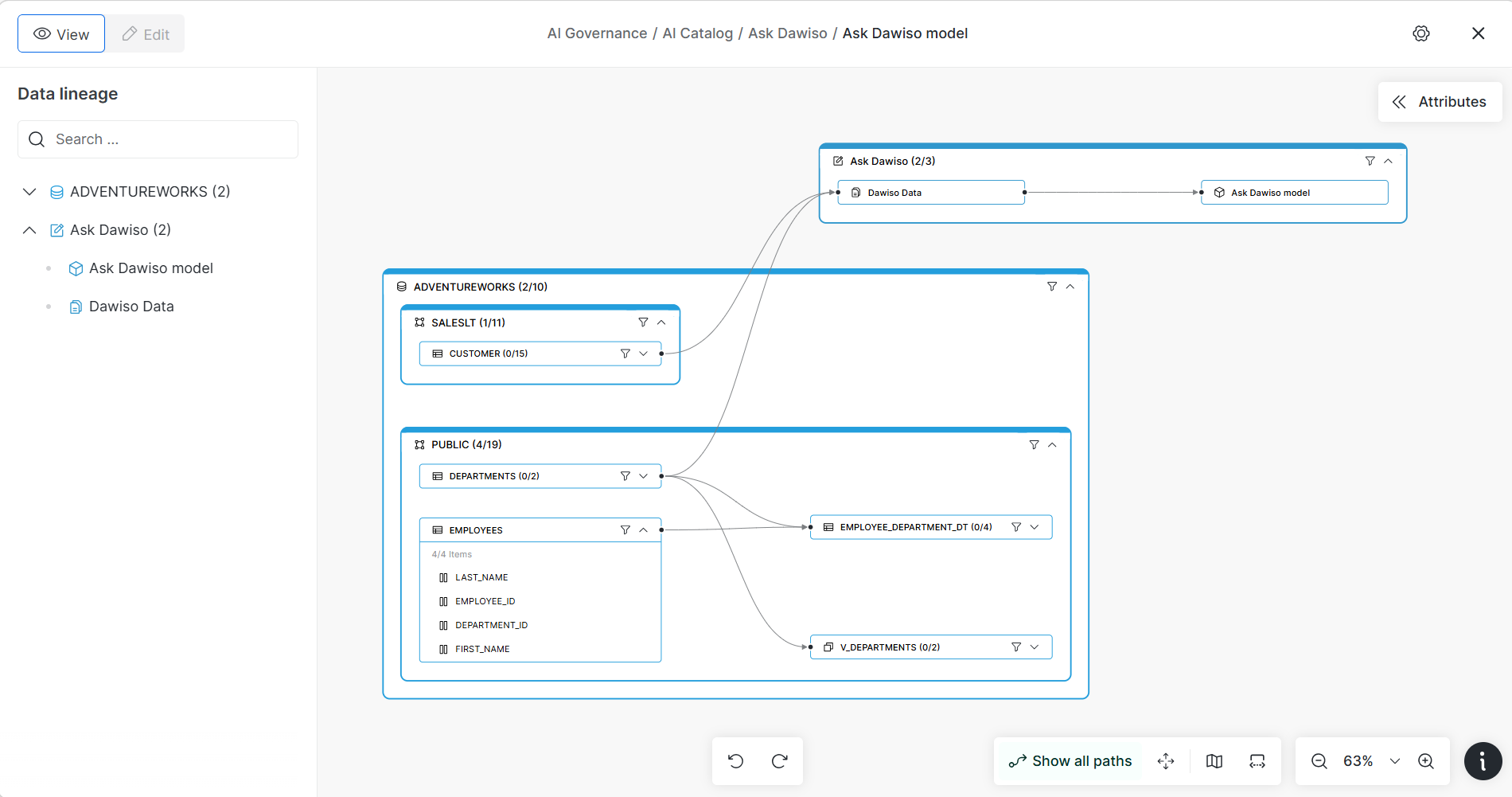
The first four steps govern context. Step five delivers it. A governed context layer is useless to AI if it stays locked in the tool that built it, so you need a standard way to expose it. That standard is the Model Context Protocol (MCP): an open protocol that lets any compatible assistant or agent connect to your context and read it on demand.
Through an MCP Server, your catalog, glossary, lineage, and classification become a single endpoint that every AI tool can query. A warehouse copilot, a BI assistant, a custom application, and an agent platform all draw on the same governed definitions and the same policies. You govern context once and serve it everywhere, instead of rebuilding it inside each tool, and the next AI tool you adopt becomes one more consumer rather than one more silo, the failure mode we describe in context silos.
Step 6: Keep It Alive with Lifecycle
A context layer is not a project you finish; it is an asset you maintain. Your business changes, definitions evolve, pipelines shift, and new sources arrive. Without a lifecycle, the layer drifts away from reality, and a context layer that quietly goes stale is more dangerous than none, because everyone still trusts it.
Lifecycle means a few concrete habits: approval workflows so definition changes are reviewed by their owners, versioning so you can see what changed and when, drift detection that flags when the underlying data no longer matches its definition (for example through schema drift), and a feedback loop that turns wrong AI answers into corrections to the context rather than one-off patches. This is governance applied continuously, and it is what keeps the layer trustworthy long after launch day.
How Long Does This Take?
The honest answer depends on whether you build the infrastructure or configure it. Building a context layer from scratch, a knowledge graph, a vector store, retrieval plumbing, and the governance around it, is a multi-quarter effort for a specialist team, and it is exactly the kind of internal build the MIT research found fails far more often than it succeeds.
On a platform that already provides the building blocks, the timeline collapses. In practice, most teams have a working catalog and business glossary within a day, and a full context layer, including AI-assisted enrichment and MCP connectivity, deployed in one to two weeks, scaling with the number of sources and the complexity of the landscape. The reason is that the hard parts, the catalog engine, the lineage graph, the policy model, and the MCP delivery, already exist. Your work shifts from building infrastructure to the thing only you can do: authoring what your business means.
How a Platform Streamlines the Work
Three platform capabilities are what turn the six steps from a research project into a configuration exercise. Unified metadata, so the catalog, glossary, lineage, and classification live in one connected model instead of four disconnected tools that each have to be integrated. Automated enrichment, so AI drafts descriptions, ownership suggestions, and classification for human review, removing the manual documentation bottleneck that stalls most governance efforts. And native governance and delivery, so approval workflows, policy enforcement, and MCP serving are built in rather than bolted on.
The combination is what makes "govern once, serve everywhere" practical. You are not stitching a catalog to a glossary to a lineage tool to a custom MCP server; you are configuring one layer where those concerns are already joined, and exposing it through one connection.
Building Your Context Layer with Dawiso
Dawiso is built to deliver exactly this path. It connects to more than 40 platforms and assembles one governed foundation across all of them: a Data Catalog (step 1), a Business Glossary (step 2), Interactive Data Lineage (step 3), and classification with governance workflows (steps 4 and 6). Dawiso AI drafts descriptions, ownership, and classification for human review, which is why the catalog-and-glossary foundation lands in a day rather than a quarter.
Through the Context Layer and its MCP Server (step 5), Dawiso serves that governed context to any MCP-compatible assistant or agent, so every AI tool reads from the same trusted definitions while your context stays owned and governed on your side. If you want the conceptual grounding behind these steps, our companion guide covers the discipline itself: context engineering for enterprise AI. The data silos took a decade to dismantle; a governed context layer is how you avoid rebuilding them one AI tool at a time.
FAQ
What is an enterprise context layer for AI?
Do we have to build the context layer from scratch?
What is the difference between a semantic layer and a context layer?
How does MCP fit into a context layer?
How does Dawiso implement a context layer?
See it in action
Dawiso Context Layer
Govern context once, then serve it to every AI tool and agent through an open protocol.


