Context Engineering for Enterprise AI: The Missing Layer Behind Trustworthy AI Answers

The model is rarely the reason enterprise AI underdelivers. The reason is context: what the model can see about your business before it answers. Context engineering is the discipline of getting that right, and it is the layer most AI programs are still missing. Here is what it is, how it differs from prompt engineering and RAG, the layers it spans, and why governed context is the part you cannot skip.
Why Better Models Are Not Fixing Enterprise AI
Most enterprises now have access to frontier-grade models, and most are still disappointed by what their AI delivers. The gap is well documented. MIT's 2025 study of enterprise AI found that 95% of generative AI pilots produced no measurable return, despite tens of billions of dollars in spending, and traced the failure not to the models but to brittle workflows and weak contextual grounding (Fortune, on the MIT NANDA report). We have written about the same pattern from the data side in why 95% of GenAI pilots fail.
The takeaway is consistent: the bottleneck is no longer raw model capability. A model that can pass a bar exam can still tell your sales team the wrong revenue number, because it does not know how your business defines revenue. The thing standing between a capable model and a trustworthy answer is context, and supplying that context deliberately is a discipline. That discipline has a name.
What Context Engineering Actually Is
Context engineering is the practice of deciding what a model sees before it answers, and making that information accurate, relevant, and governed. A model produces an answer from whatever sits in its context at the moment of the request. Context engineering is the work of assembling that window on purpose, rather than hoping the model already knows enough or that a clever prompt will paper over the gaps.
In an enterprise setting, the context a model needs is made up of several distinct ingredients:
- System instructions that set the model's role, tone, and boundaries.
- Retrieved knowledge pulled from your documents, tables, and applications for the specific question at hand.
- Business meaning, the definitions of metrics and entities and the relationships between them, so the model knows what your data means.
- Tool definitions and outputs when the model can call functions, query systems, or take actions.
- Memory and conversation history so the model carries relevant prior state.
- Governance signals, the classification, access rules, ownership, and trust indicators that say what the model may use and how far it can rely on it.
Get this mix right and a competent model becomes genuinely useful on your data. Get it wrong, or leave it to chance, and the same model hallucinates, contradicts itself across tools, or acts on a definition nobody agreed to.
"The model is the engine. Context is the fuel, the map, and the rules of the road."
Context Engineering vs. Prompt Engineering
Prompt engineering and context engineering are often confused, and the difference matters because it determines who owns the problem. Prompt engineering optimizes a single exchange: how you phrase the question, the examples you include, the instructions you give the model for one answer. It is a valuable individual skill, and it has a ceiling. No amount of prompt tuning can supply a definition the model was never given.
Context engineering optimizes the system around every prompt: which sources are retrieved, how business meaning is injected, what is filtered out, how governance is enforced, and how all of it is assembled before the model ever sees the question. Prompt engineering is something a person does. Context engineering is an architecture a data team builds and owns.
Is This Just RAG With a New Name?
It is a fair question, because retrieval-augmented generation (RAG) looks a lot like context engineering from a distance. Both put extra information in front of the model. But RAG is a technique, and context engineering is the discipline that decides how and when to use it.
RAG answers one question: given a query, which documents or rows should I fetch and paste into the prompt? That is necessary, and it is not sufficient. RAG retrieves text that looks relevant; it has no opinion on whether that text is authoritative, what the terms in it mean, who is allowed to see it, or whether two retrieved sources contradict each other. RAG retrieves content; context engineering retrieves trustworthy meaning.
Context engineering wraps retrieval in the things that make it safe to rely on: a governed definition of each business term so the model interprets the retrieved data correctly, classification so sensitive fields are handled appropriately, and lineage so an answer can be traced back to a trusted source. Skip that layer and RAG happily retrieves a stale spreadsheet and a deprecated metric with equal confidence.
The Layers of Enterprise Context
It helps to think of enterprise context as a stack. Each layer answers a different question, and each is owned by someone different. When AI underperforms, the problem is almost always one specific layer, which makes the stack a useful diagnostic as much as a design.
- System layer — the model's role, instructions, and guardrails. Answers: how should the model behave?
- Retrieval layer — the documents, tables, and records fetched for the question. Answers: what is relevant right now?
- Semantic layer — the business glossary and metric definitions. Answers: what does this data mean in our business?
- Governance layer — classification, access rules, and policy. Answers: what is the model allowed to use, and how?
- Provenance layer — lineage and trust signals. Answers: where did this come from, and can we rely on it?
The top two layers are where most teams start, because they are the visible ones. The bottom three are where most teams fail, because they are the governed ones, and they are exactly the layers a model cannot reconstruct for itself.
Why a Bigger Context Window Is Not the Fix
A tempting shortcut is to skip the engineering and let the long context window do the work: dump everything the model might need into a giant prompt and trust it to find what matters. The research says this backfires. As input length grows, model accuracy degrades, a failure mode increasingly called context rot.
Chroma's 2025 study tested eighteen frontier models and found that every one performed worse as more tokens were added, at every length tested (Chroma, "Context Rot"). Earlier work documented the related "lost in the middle" effect: models use information at the start and end of a long context far more reliably than information buried in the middle (Liu et al., 2023). Irrelevant but similar-looking content does not sit there harmlessly; it actively pulls the model toward wrong answers.
The goal is not to give the model the most context. It is to give it the right context. A precise, governed, well-ordered context of a few thousand tokens beats a noisy hundred-thousand-token dump every time, and it is cheaper to run.
This is exactly the value context engineering adds over "just retrieve more." It curates. It supplies the governed definition instead of ten documents that mention the term, and it leaves out the distractors that would otherwise degrade the answer.
What Changes When Agents Replace Analysts
So far this reads as an analytics problem: an AI assistant answers a question, a human reads the answer, and a wrong number is caught in review. Agents remove the human from that loop. An agent does not just answer; it acts, chaining steps and calling tools to complete a task across systems.
That raises the stakes on context in two ways. First, an agent makes many model calls in sequence, so a single misunderstanding compounds across every downstream step. Second, a wrong answer is no longer a sentence somebody double-checks; it is an action taken at machine speed, propagated before anyone notices. Context engineering for agents therefore has to be more disciplined, not less: every step needs the right governed context, and the agent needs to know which sources are authoritative and which data it is permitted to touch. The cost of a context gap moves from "embarrassing" to "operational."
This is also why fragmented context becomes dangerous in the agent era. When every agent platform builds its own private store of meaning, you get inconsistent, ungoverned context multiplied across tools, a pattern we cover in context silos.
Where MCP Fits in the Stack
If context engineering is about supplying governed context to a model, something has to carry that context from where it is governed to where it is consumed. That is the role of the Model Context Protocol (MCP), an open standard for connecting AI applications to external context and tools.
MCP matters because it decouples the two halves of the problem. You govern context once, in infrastructure you own, and you expose it through a single standard connection. Then any MCP-compatible assistant or agent, a warehouse copilot, a BI tool, a custom build, or an agent platform, reads from the same governed source instead of inventing its own. MCP is the delivery layer that turns a governed context layer into something every tool can consume, without you re-implementing context for each one. It is the difference between engineering context once and re-engineering it in every tool forever.
Governance Is the Foundation of Context Quality
Everything above converges on one point: you cannot engineer context you do not govern. The semantic, governance, and provenance layers are not optional polish on top of retrieval; they are the part that makes the context trustworthy, and they are precisely the part a model cannot generate for itself.
A model can summarize a document. It cannot tell you that the document is the approved source rather than a draft, that "active customer" excludes churned trials this quarter, that a column contains PII that must be masked, or that a metric was deprecated last month. Those are governance facts, authored and maintained by people, and they are the difference between an answer that looks right and one that is right. Context quality is downstream of governance quality. If your definitions are scattered across wikis, spreadsheets, and individual heads, your AI inherits exactly that fragmentation, no matter how good the model is.
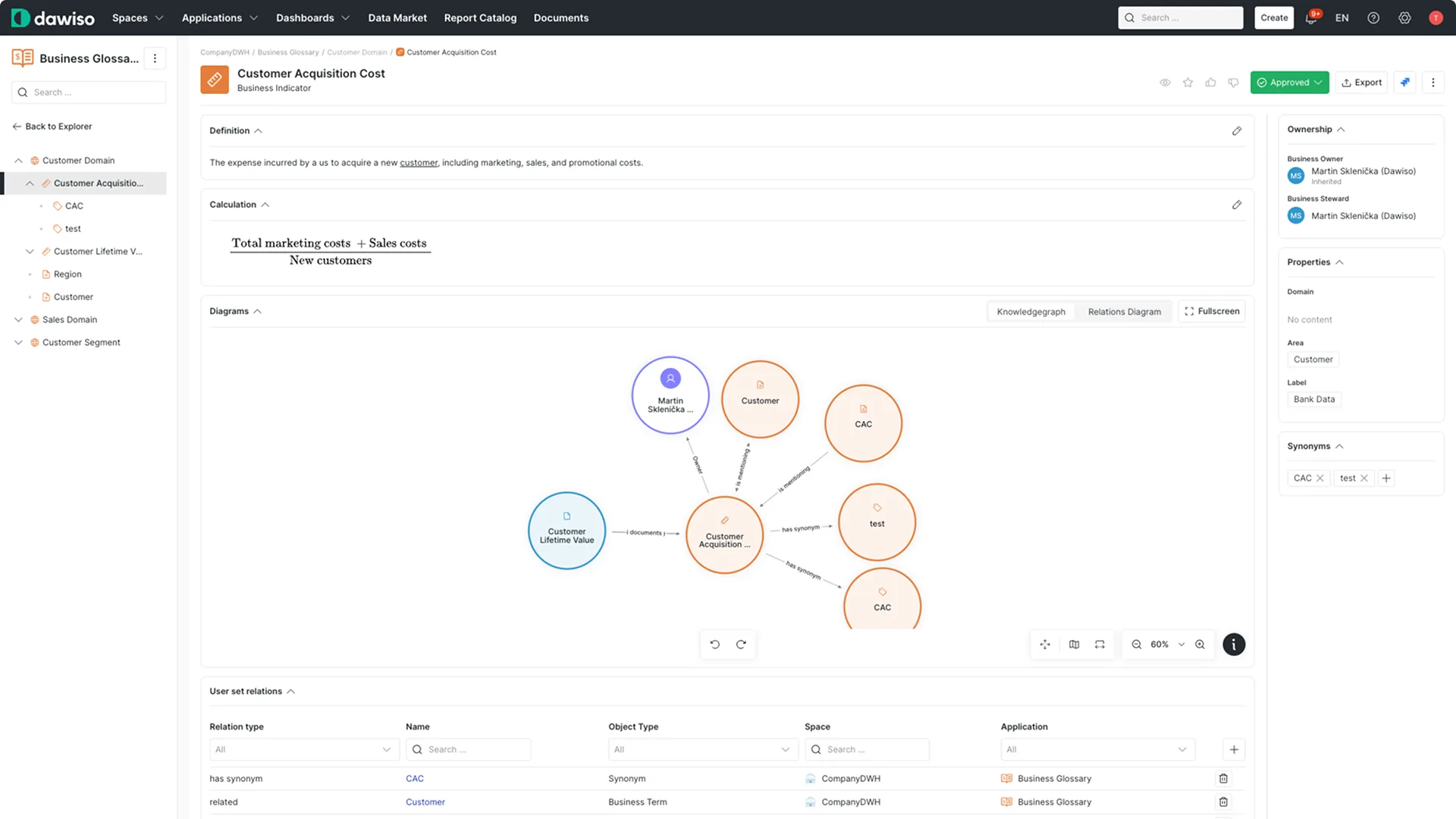
How Dawiso Builds the Context Layer
This is the job Dawiso is built for. It connects to more than 40 platforms and assembles one governed foundation across all of them: a Data Catalog of what exists, a Business Glossary of what each term means, classification of what is sensitive, and Interactive Data Lineage of where everything came from. Dawiso AI helps generate descriptions, ownership suggestions, and classification for human review, so the governed layer can be built in days rather than quarters.
Through the Context Layer and its MCP Server, Dawiso serves that governed context to any MCP-compatible assistant or agent. The semantic, governance, and provenance layers, the three most teams skip, become a single owned asset that every AI tool reads from. Your context is engineered once, governed in one place, and consumed everywhere, which is the whole point of context engineering done at enterprise scale.
When you are ready to build the layer itself, our companion guide walks through it step by step: how to implement an enterprise context layer for AI.
FAQ
What is context engineering in simple terms?
How is context engineering different from prompt engineering?
Is context engineering just retrieval-augmented generation (RAG)?
Why does a bigger context window not solve the problem?
How does Dawiso support context engineering?
See it in action
Dawiso MCP Server
Serve governed business context to any LLM or agent through an open protocol.


