RAG vs Semantic Layer: What's the Difference?

Enterprise AI systems need context to provide accurate, trustworthy answers. But confusion persists about two critical approaches for delivering this context: RAG (Retrieval-Augmented Generation) and semantic layers. Understanding when to use RAG, when to implement a semantic layer, and how they differ is essential for building effective AI systems.
Both RAG and semantic layers are methods for delivering context to AI. This is the foundation of understanding the relationship between them. They work similarly in principle: a chatbot or AI agent connects to either RAG or a semantic layer to retrieve relevant information. The key difference lies in what type of data they handle and how they provide that context.
What is RAG (Retrieval-Augmented Generation)?
When discussing RAG in AI contexts, we're primarily talking about RAG as a technology, a specific approach to storing and retrieving information using vector databases. This is distinct from RAG architecture, which is a broader system that incorporates RAG technology along with other components.
RAG Technology: The Core Components
At its core, RAG technology consists of three fundamental components:
- Vector Database with Embeddings
- Search Engine (vector similarity search)
- Embedding Strategy (how the database is populated)
Understanding Embeddings
Embeddings are the foundation of RAG technology. An embedding is essentially a segment of text that has been converted into a numerical vector representation. The strategy for creating embeddings is critical:
Creating Embeddings:
- Take a source document (e.g., a 30-page report)
- Split it into smaller chunks using various strategies:
- By sentences
- By paragraphs
- By chapters or logical sections
- By punctuation markers
- By fixed character lengths (e.g., 150 characters)
- …
- Each chunk becomes an individual entry in the vector database
- For each chunk, calculate a vector (a multi-dimensional number)
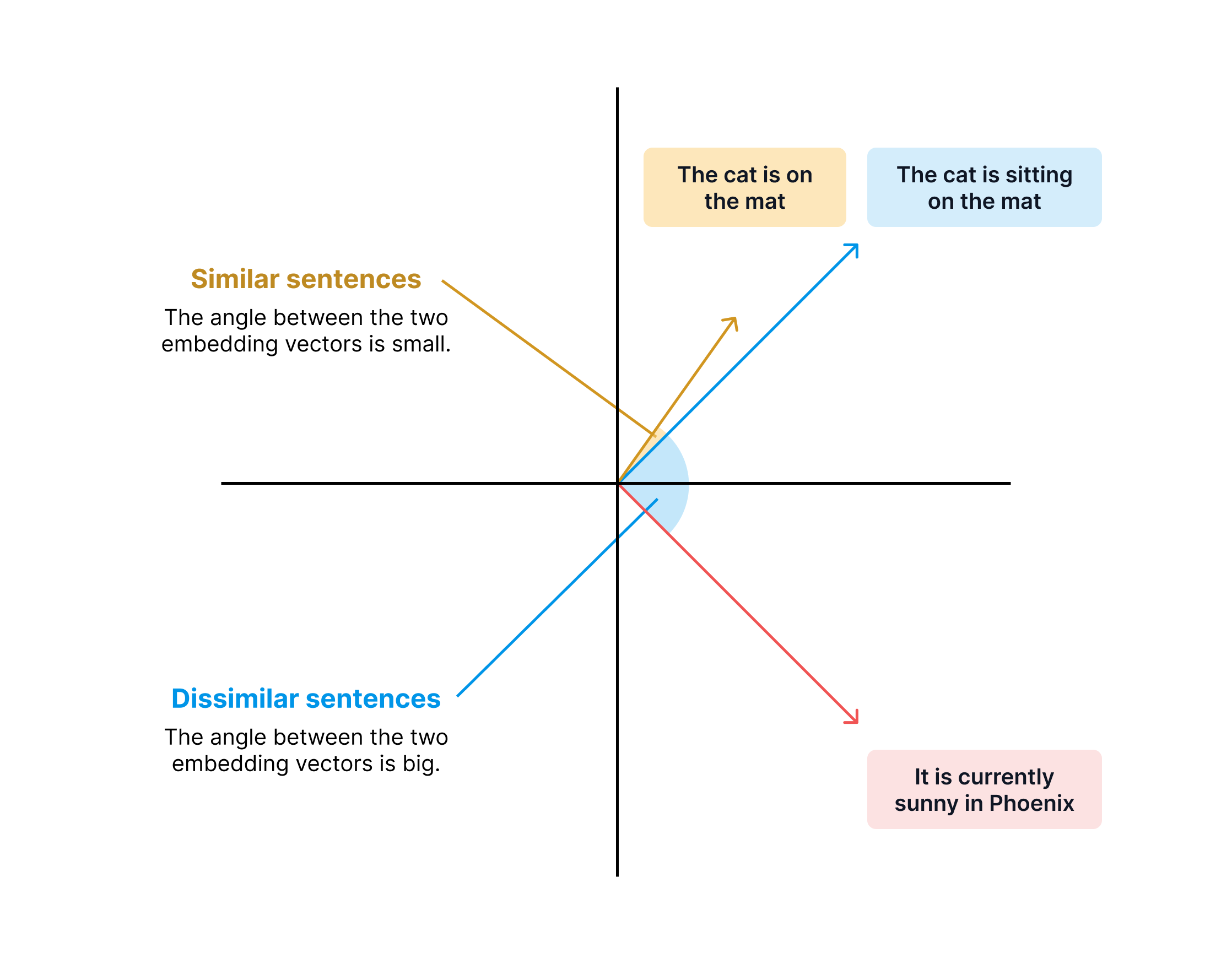
How RAG Retrieval Works:
- When a query arrives from the AI, calculate a vector for that query
- Compare the query vector against all embedding vectors in the database
- Find embeddings with the shortest vector distance (closest match)
- Return the most relevant text chunks
- Feed these chunks to the LLM for response generation
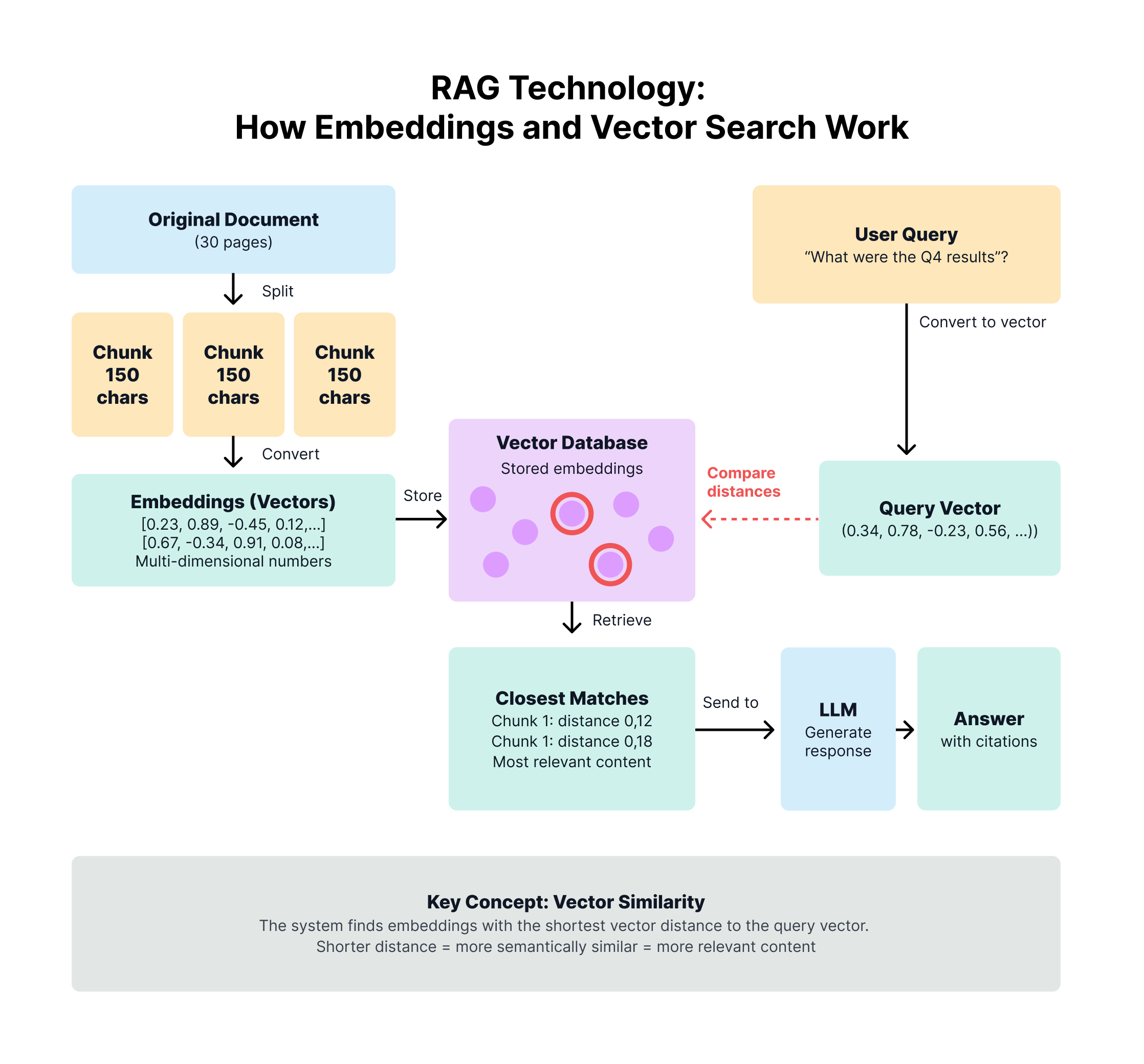
The system can return just the embedding, the full document containing the embedding, or multiple embeddings, depending on the specific use case.
Why RAG Matters for Enterprise AI
RAG has become essential because it solves a fundamental problem: large language models can only know what they were trained on, and that training data has a cutoff date. According to AWS, RAG extends the capabilities of LLMs to specific domains or an organization's internal knowledge base without the need to retrain the model.
When you ask an LLM about recent events, internal company data, or specialized domain knowledge, it often generates plausible but incorrect information, known as hallucinations. As explained by IBM, RAG addresses this by giving AI systems access to up-to-date, domain-specific knowledge at query time.
RAG Example
Consider a pharmaceutical company implementing RAG for its research team. When a scientist asks, "What were the adverse events in our Phase 2 trial for compound XYZ-123?" the system retrieves specific clinical trial documentation, regulatory submissions, and safety reports. The LLM then generates an accurate response grounded in the company's actual data, complete with citations.
RAG: Strengths and Limitations
Advantages:
- Excellent for unstructured text - Can search through documents, PDFs, reports that SQL can't touch
- Semantic similarity search - Finds relevant information even when exact keywords don't match
- Source attribution - Provides citations to specific document sections
- Reduces hallucinations for text-based questions - Grounds answers in actual documents
Limitations:
- Only works with text/documents - Can't query structured databases
- Quality depends on document quality - Garbage in, garbage out
- Retrieval quality matters - If the search finds the wrong documents, answers will be wrong too
- Added latency - Extra retrieval step
- Governance risks - May surface unauthorized data without proper controls
Critical Understanding: RAG is designed specifically for unstructured data (documents, text files, PDFs, reports). It's a specialized technology for working with text that can't be queried with traditional methods like SQL.
What is a Semantic Layer?
A semantic layer is fundamentally different from RAG in its scope and purpose. While RAG is a specific technology for unstructured text retrieval, a semantic layer is a broader approach for collecting and organizing large volumes of information, both structured and unstructured.
A semantic layer sits between raw data sources and AI applications, translating technical database structures into business-friendly concepts. According to Wikipedia, it converts metadata from data sources into a cross-organization semantic knowledge graph.
Key Components of a Semantic Layer
A modern semantic layer typically combines multiple technologies:
- Knowledge Graph - Structured relationships between data entities and business concepts
- Structured Information Repository - Searchable databases of business terms, definitions, and metadata
- Business Glossary - Centralized definitions ensuring consistent understanding
- Metadata Repository - Comprehensive information about data assets (technical, business, and operational metadata)
The Universal Translator for Data
Think of a semantic layer as a universal translator for your data. Your databases contain technical field names like "cust_purch_amt_ytd" that make sense to engineers but confuse business users. The semantic layer maps these to business concepts like "Customer Annual Purchase Amount" and ensures "Revenue" means the same thing across sales, finance, and operations.
For AI systems, the semantic layer is even more critical. When an AI agent needs to query data, it must understand:
- What the data means in business terms
- How different metrics relate to each other
- Which definitions are authoritative
- Data lineage and quality
RAG vs Semantic Layer: The Core Differences
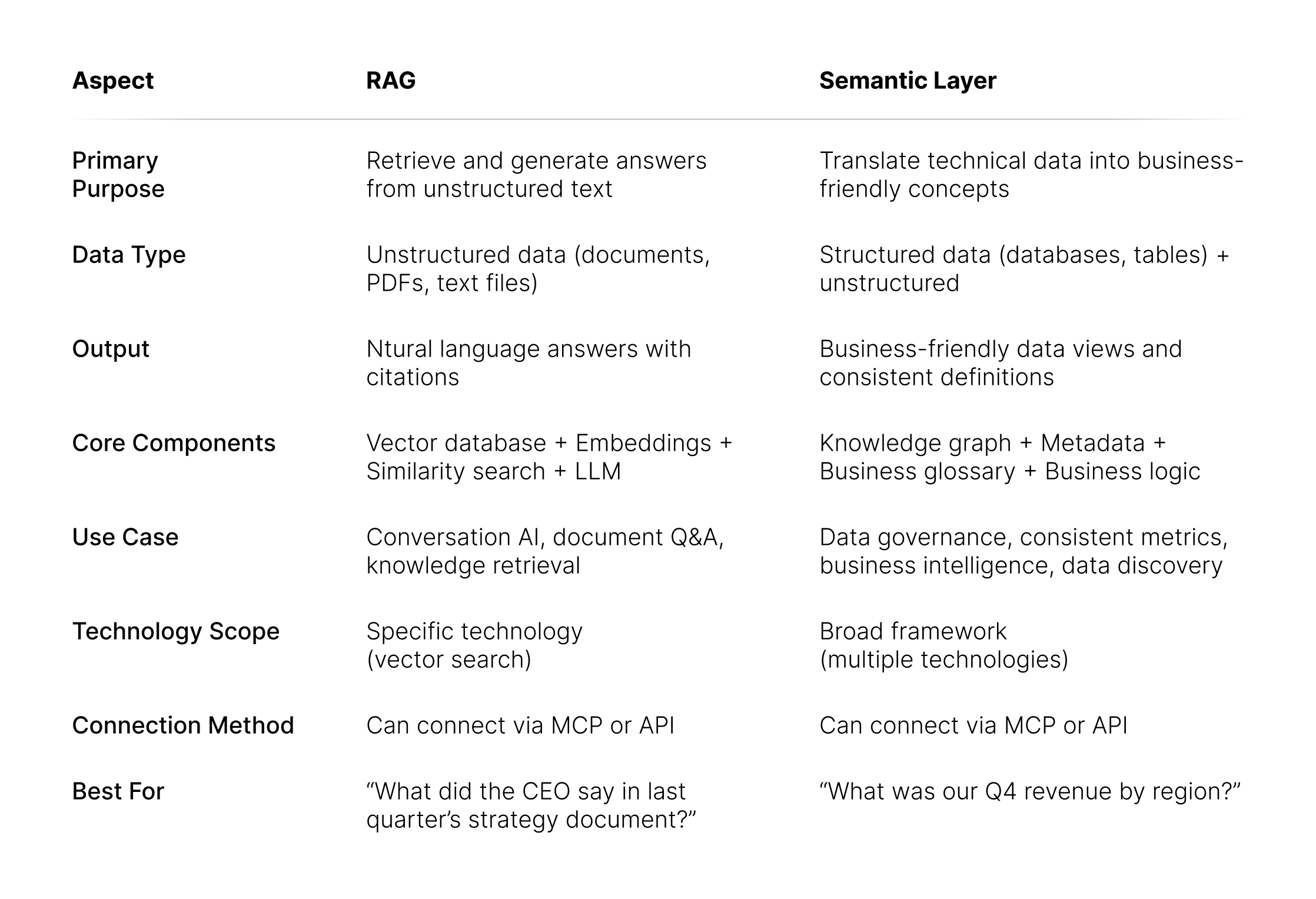
Key Distinctions
1. Data Type Focus
RAG:
- Works only with unstructured data (documents, text, PDFs)
- Requires text content to create embeddings
- Not suitable for structured database queries or creating business context
Semantic Layer:
- Handles both structured and unstructured data
- Describes structured data relationships through knowledge graphs
- Captures lineage and relationships in structured data
- Can incorporate RAG technology as one component
2. Use Cases
RAG:
- Document search and retrieval
- Question answering from text sources
- Knowledge base queries
- Conversational AI over documentation
Semantic Layer:
- Business intelligence and analytics
- Cross-organizational data consistency
- Data discovery and governance
- AI agents querying structured databases
- Creating a comprehensive business context
3. Technology vs. Framework
RAG is a specific technology with a defined implementation (vector database + embeddings + similarity search).
Semantic Layer is a broader framework that combines multiple technologies to provide business context. A semantic layer can even include RAG as one of its components.
The Relationship: Complementary, Not Competitive
RAG and semantic layers are not competing solutions. It is important to mention that these two solutions serve different purposes and are often used together.
Consider these scenarios:
- RAG only: You need to search internal documentation, policies, or research papers
- Semantic layer only: You need to query structured business data with consistent definitions
- Both together: You need to answer "How does our Q4 revenue compare to what the CEO projected in the strategic plan?" (requires structured data query + document retrieval)
Modern enterprise AI often requires both approaches. Users ask questions that span structured database queries and unstructured document retrieval. The semantic layer can even govern which documents flow into RAG, leveraging metadata about ownership and permissions.
Key Takeaways
- Both are context delivery methods - RAG and semantic layers are ways to provide context to AI systems, and both can connect via protocols like MCP (Model Context Protocol)
- Data type determines choice - Use RAG for unstructured text, semantic layers for structured data (and comprehensive business context), and unstructured data
- Different scopes - RAG is a specific technology; semantic layers are broader frameworks
- Often combined - Enterprise AI systems frequently need both to work together
- Not competitors - They solve different problems and complement each other
Understanding these distinctions helps organizations design AI systems that deliver accurate, trustworthy answers by combining the right technologies for their specific needs.
In our next article, we'll explore how RAG and semantic layers work together in practice, and how modern context layer solutions address both structured and unstructured data challenges simultaneously.


