How to Use AI in the Data Landscape: What Actually Works in 2025

Artificial intelligence is everywhere in 2025. From copilots in dashboards to generative models summarizing reports, AI is increasingly embedded into the workflows of data teams. But amid the buzz, a critical question remains: which AI tools actually support data work and which just add noise? This article offers practical recommendations for how data engineers, analysts, and governance professionals can use AI tools that truly deliver value. We explore what general LLMs can and cannot do, why embedded AI is more effective, and why metadata is the foundation for AI that works.
1. General LLMs: Useful, But Not a Complete Solution
While generative models like ChatGPT or Claude offer impressive capabilities on the surface, many fall short when applied to the complex realities of enterprise data environments. The real challenge is not just adding AI, but integrating it meaningfully into data operations, workflows, and governance.
General large language models (LLMs) such as ChatGPT, Claude, and Gemini have become popular for tasks like:
- Drafting documentation
- Generating SQL queries
- Summarizing meeting notes or technical descriptions
These tools offer immediate productivity boosts, particularly for individual users. However, when it comes to working with structured data environments, they quickly hit their limits.
General-purpose LLMs lack access to:
- Internal metadata and documentation
- Business glossaries and rules
- Real-time visibility into the organization’s data architecture
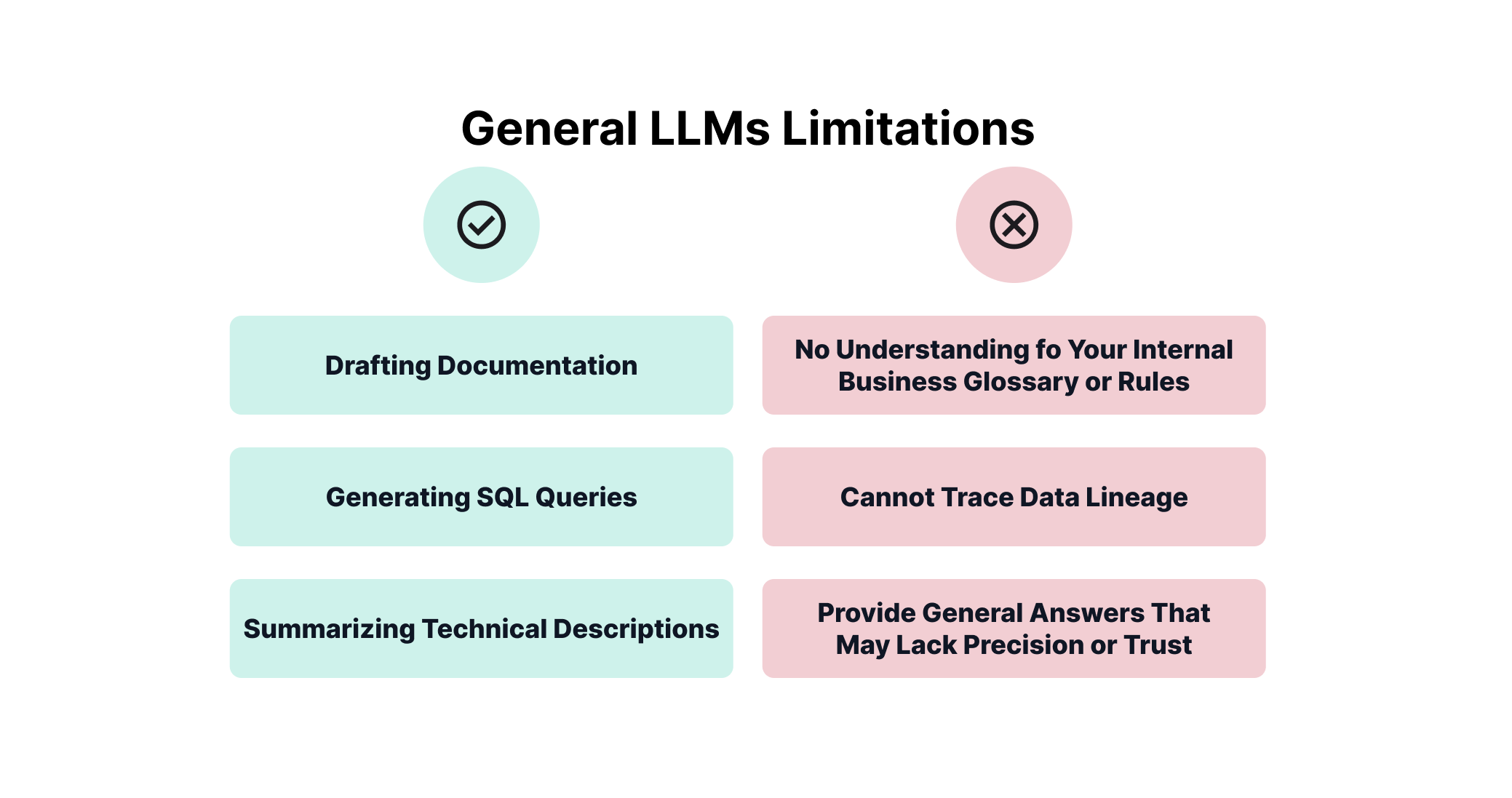
As a result, they cannot provide context-aware recommendations, validate data logic, or assist meaningfully in decisions that rely on data accuracy, lineage, or ownership. They are helpful, but not sufficient.
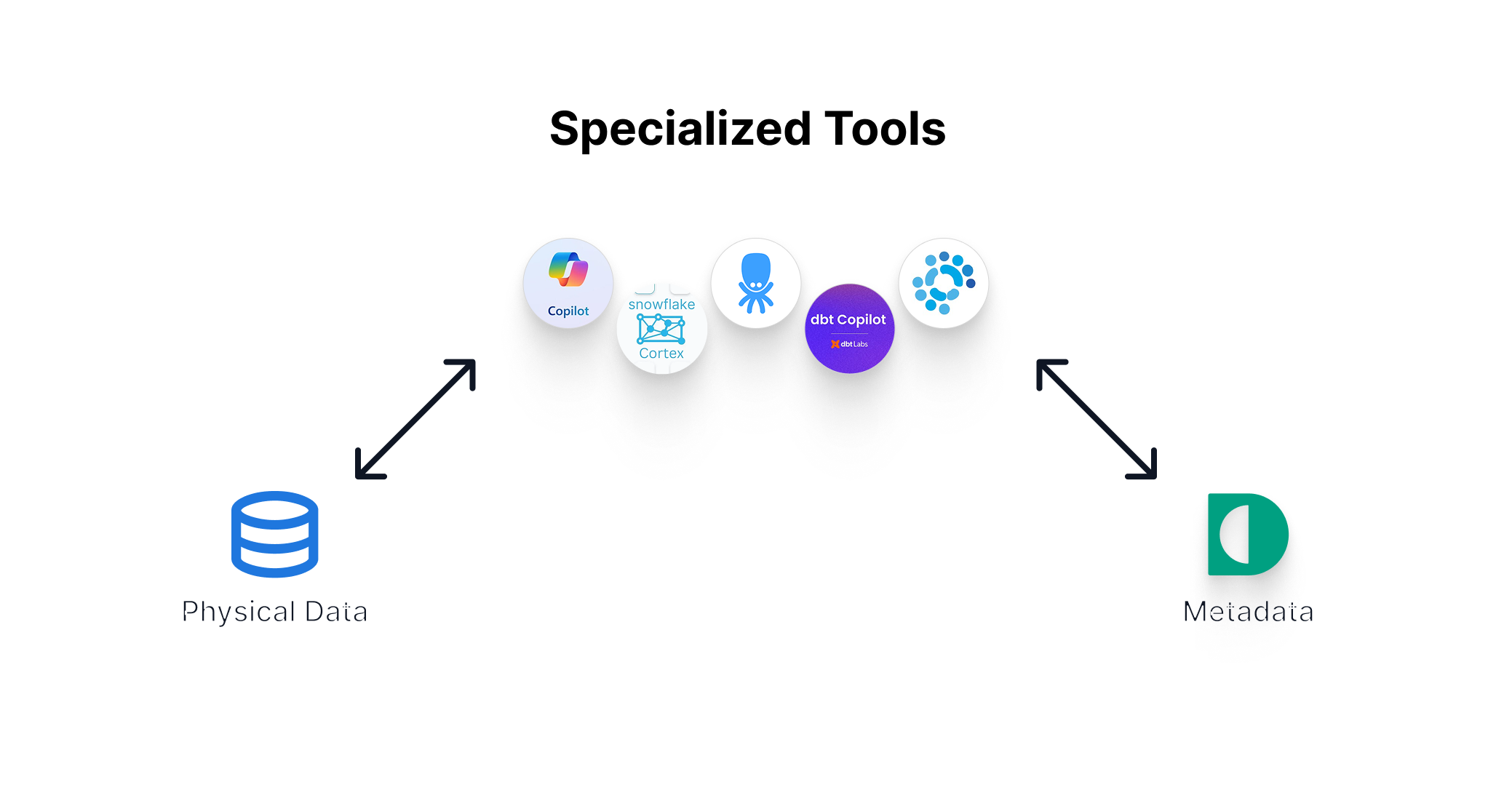
2. Specialized AI tools
More promising are specialized AI tools built directly into widely used data platforms.
Top 5 specialized AI tools
- Snowflake Cortex
- dbt Copilot
- Copilot for Power BI
- Keboola’s Model Context Protocol (MCP)
- Waii
- ...and similar metadata-aware copilots
These embedded tools offer assistance exactly where work happens. They can:
- Recommend SQL or dbt model logic
- Autofill dashboard content
- Detect data quality anomalies
- Suggest transformations based on schema or lineage
But even these tools rely on having access to well-maintained metadata. Without clearly defined terms, trusted lineage, and context-rich documentation, their recommendations remain limited in relevance and accuracy. In other words, their usefulness is directly tied to the quality and accessibility of metadata across the organization.
3. Metadata base for AI
AI without metadata produces unreliable results.
The most impactful use of AI in the data landscape is not tied to any single tool. It begins with creating a strong metadata foundation that AI systems can access, understand, and act on.
Platforms like Dawiso address this need by enabling organizations to:
- Organize business glossaries and KPI definitions
- Automatically map data lineage
- Document transformations and workflows
- Provide AI features access to this structured knowledge
This foundation enables copilots and LLMs to deliver intelligent, contextual suggestions. Before scaling AI usage, build a metadata layer that connects business language with technical reality. Without it, even the best AI tools underperform.
The Role of Metadata in Reliable Results
Metadata, which refers to data about data, is crucial for AI systems to produce accurate, relevant, and trustworthy results. It offers essential context that helps both users and machines understand not just what the data is, but also how it should be utilized. Metadata captures important details such as the nature of the data, its properties, how to use it, and how to combine it with other data. This context enables clearer interpretations, more effective collaborations, and smarter, more advanced uses of data.
What works in 2025: A clear direction for data teams
The hype around AI will continue, but so will the confusion, unless teams take deliberate steps to integrate AI with governance, documentation, and transparency. What works in 2025 is not AI in isolation, but AI embedded in systems that:
- Understand your data context
- Respect your governance structures
- Support human collaboration and trust
AI is only as useful as the data context you give it.
Conclusion:
One of the most frequent and overlooked gaps in AI initiatives is the absence of a strong metadata foundation. Without it, organizations often find themselves stuck, able to build promising prototypes, but unable to scale them into reliable, production-ready systems. Bridging that gap begins with making metadata a first-class priority.
The impact of AI ultimately depends on how well it performs in real-world use. In the case of internal Q&A tools or AI copilots, a reliable indicator of success is simple: regular usage. Frequent use reflects both trust in the system and the quality of its responses. But trust requires context. And without structured metadata, like data definitions, quality indicators, and lineage, AI lacks the grounding it needs to deliver accurate, relevant, and dependable results.
The most effective AI teams look beyond model training and algorithms. They focus on the broader architecture where metadata plays a central role. It provides the context that makes outputs meaningful, helps systems adjust to changes, and ensures AI isn’t just generative, but genuinely helpful.
For AI to be sustainable and trusted at scale, leaders must rethink their strategy with metadata readiness at the core. Doing so creates conditions for better performance, smoother integration, and ultimately, a more intelligent and resilient AI layer across the business.


