Data Ingestion Architecture in Dawiso Explained

Dawiso’s data ingestion architecture is designed to adapt to any infrastructure, whether cloud-based, on-premises, or hybrid. It gives organizations full control over how metadata is retrieved, with flexible options that respect internal security policies and technical constraints. In this article, you’ll get a clear look at how Dawiso handles metadata ingestion, how it fits into the overall platform architecture, and why it works equally well for modern data stacks and more complex legacy environments.
Dawiso architecture overview
Dawiso’s platform is structured into three primary components, each designed to work together:
Dawiso Product: The main interface and control center where users interact with the platform. It connects other modules and enables access to data catalogs, glossaries, lineage, and more.
Dawiso Internal AI: An intelligence layer providing AI-driven features such as recommendations and metadata suggestions.
Dawiso Data Ingestion Module: Responsible for retrieving metadata from various source systems and populating the Dawiso environment.
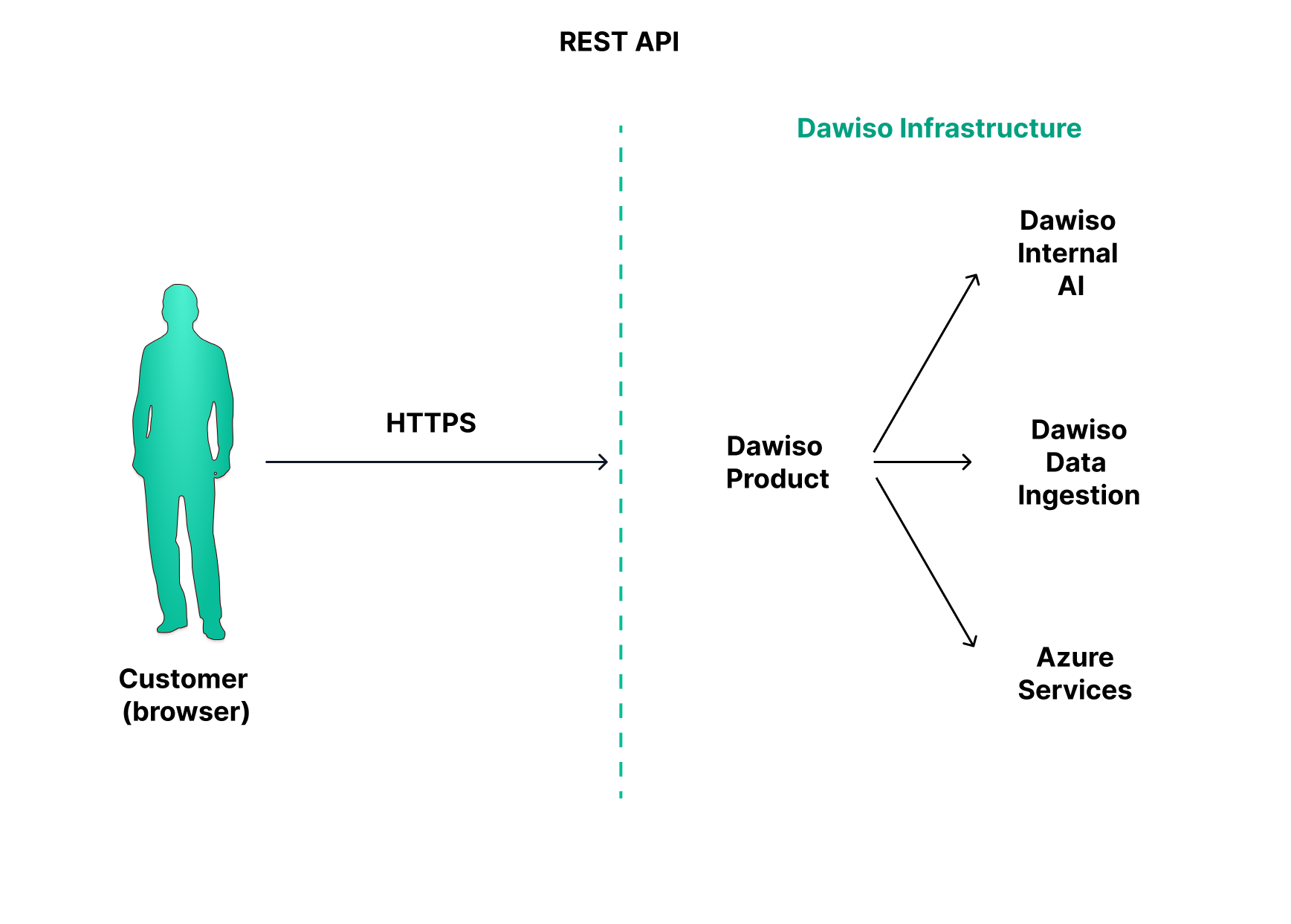
All these components can run securely in the cloud, built on Azure infrastructure, or be deployed on-premises, depending on the customer’s environment. In cloud setups, Dawiso can optionally integrate with OpenAI for enhanced natural language capabilities. Regardless of the deployment model, the platform is accessed through a browser using standard HTTPS protocols, ensuring secure communication between Dawiso and the customer environment.
Two modes of ingestion: push and pull
Dawiso offers two distinct approaches for bringing metadata into the platform: push mode and pull mode. Both achieve the same outcome - importing metadata from your systems into Dawiso, but give you different levels of control, depending on your infrastructure and security needs.
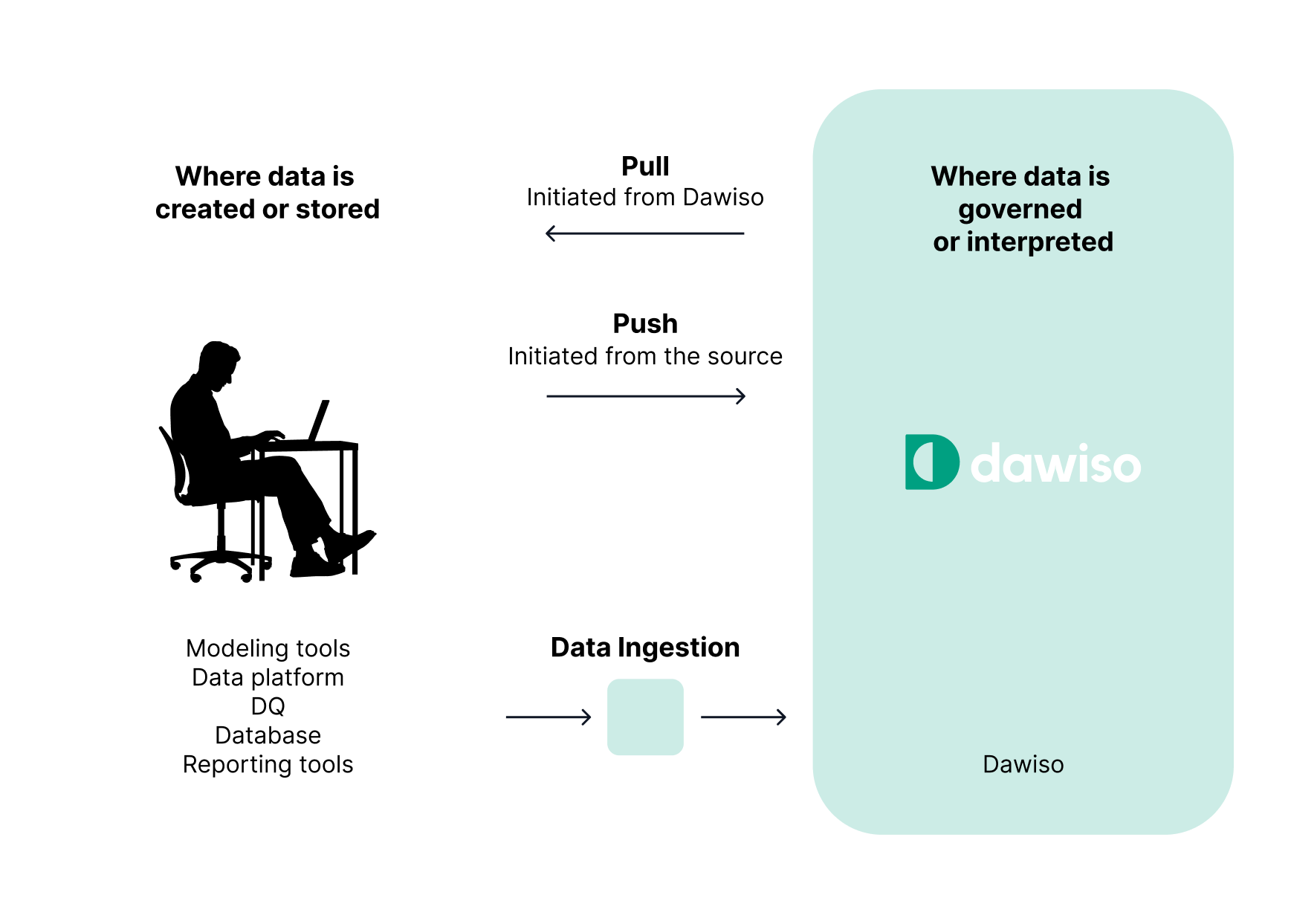
Push mode (Controlled, secure, customer-led ingestion)
In push mode, the process runs entirely on your side. You install a small utility called Dawiso Integration Runtime (DIR), configure it with access to your internal systems, and let it handle the extraction and secure transfer of metadata to Dawiso. A key benefit of this setup is that you have full control over the scheduling. You can decide when metadata is extracted into DIR, for example, every night at 3 a.m., and independently choose when that metadata is pushed from DIR to Dawiso. This separation gives you the option to review or validate metadata locally before sending it onward. It’s especially useful in environments with strict governance or auditing requirements.
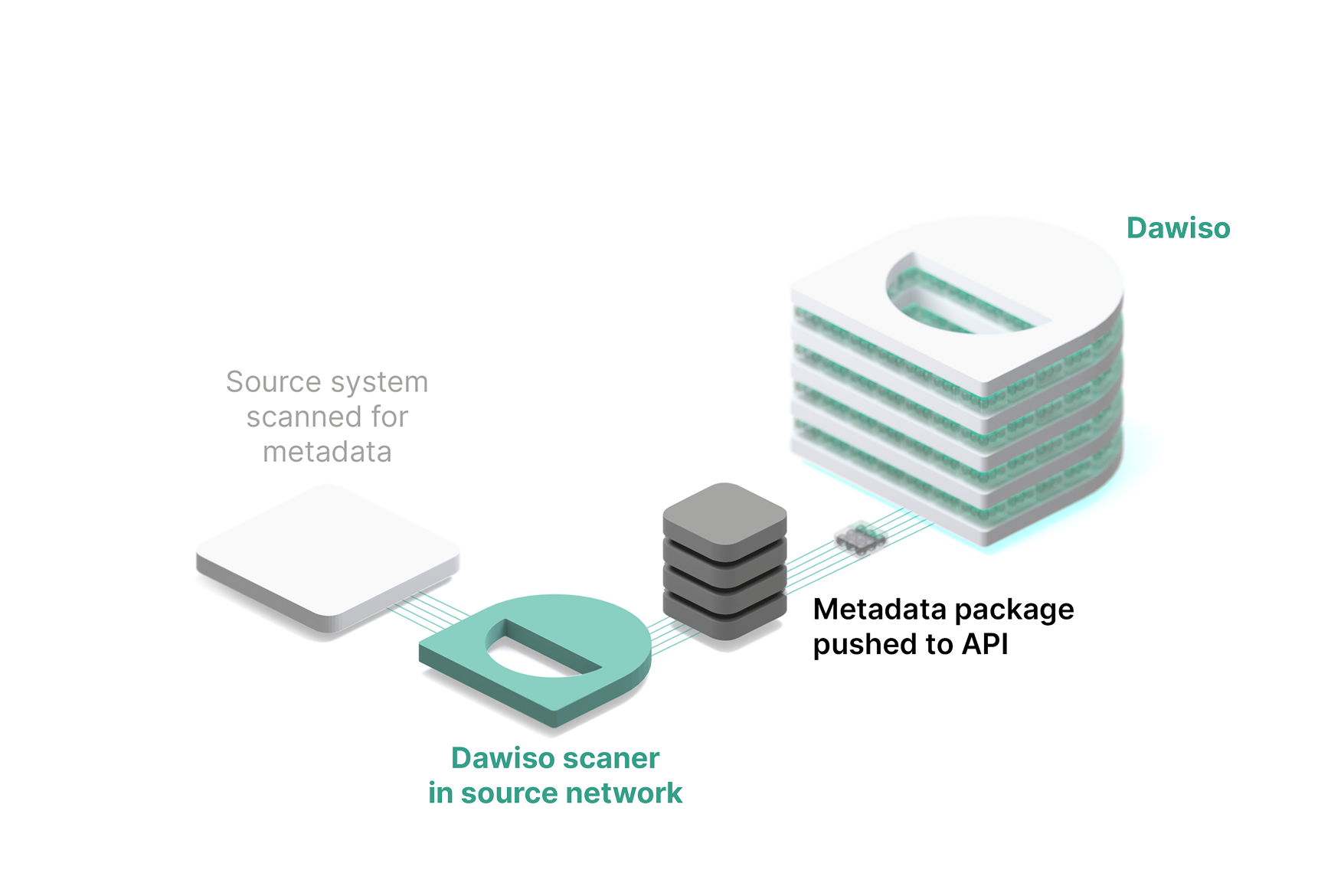
Think of it like this: you’re invited to our office, and we give you a key to one room. You come in, do what you need to do, and leave when it suits you. No one else needs to know what you accessed internally, you’re in charge the whole time. This mode is ideal for organizations with strict access policies or isolated environments.
In push mode, the customer initiates the metadata ingestion process using a provided executable file (Dawiso-Ingestion.exe). This binary runs within the customer's own environment, connects to the specified data sources, extracts metadata, and securely pushes it to Dawiso using HTTPS.
- Ideal for: Organizations with strict security policies that prevent external systems from accessing internal data sources.
- Key advantage: Full control over what is shared, how often ingestion runs (e.g., nightly via Windows Scheduler), and which metadata are sent to Dawiso.
- Additional note: Metadata is often extracted into gzip-compressed files and transmitted securely.
Pull mode (Hands-off, Dawiso-managed ingestion)
In pull mode, it works the other way around. Dawiso is given secure credentials to access source systems (e.g., Snowflake, SQL Server) and connects directly to retrieve metadata. You can still define when the ingestion should run, for example, during off-peak hours, but there’s no DIR component in between. The extraction and transfer occur in a single scheduled step, fully managed by Dawiso automatically. This simplifies setup and reduces maintenance, while still giving you control over when metadata is collected.
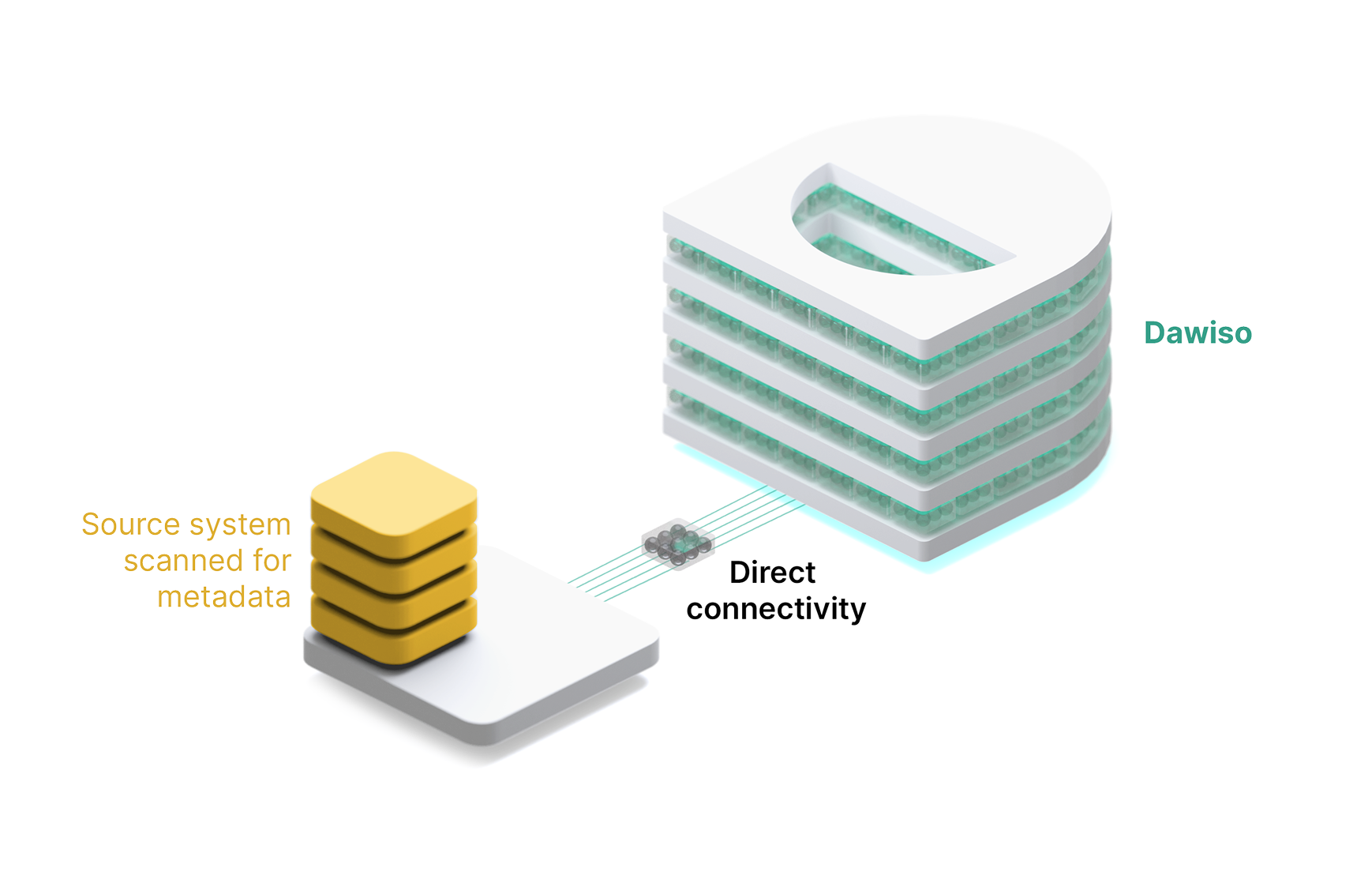
This time, imagine you come to our office, but everything you’re not supposed to touch is clearly marked and taped off. You can only see and take what’s freely available. It’s easy, secure, and controlled on our side, no need for you to manage anything.
- Ideal for: Customers who prefer a plug-and-play approach without managing ingestion scripts.
- Key advantage: Minimal setup required by the customer; Dawiso handles everything from connection to ingestion.
Both modes support cloud and on-premise environments and are backed by the robust Dawiso Ingestion Engine, capable of handling millions of metadata assets and frequent updates with ease.
Advantages of Dawiso’s ingestion architecture
- Security and Flexibility: Customers choose the approach that best fits their infrastructure and security policy, without compromising capability.
- Scalability: Designed to handle enterprise-scale metadata volumes.
- Cross-platform: Works across Windows, Linux, cloud, and on-premise systems.
- Customizable Scheduling: In push mode, ingestion can run on custom schedules (e.g., nightly).
- Visibility: Users can inspect extracted metadata before sending it to Dawiso.
- Resilience: Metadata ingestion is independent of source system uptime in push mode.
- Write-back Support: In addition to reading from sources, Dawiso can also write metadata (e.g., definitions, labels) back into tools like Tableau using REST API.
Connection types: Shared and Private
To better align with different security and access requirements, Dawiso also distinguishes between shared and private connections.
A shared connection means Dawiso connects directly to your systems using credentials you’ve provided. It’s simple to set up and works well when there are no technical or legal barriers to remote access.
A private connection is used when direct access isn’t possible. For instance, when the source system is behind a firewall or not reachable from the public internet. In these cases, the Dawiso Integration Runtime (DIR) is used to run ingestion jobs locally, keeping all network communication outbound and fully under your control.

Dawiso Integration Runtime (DIR): What it is and how it works
The Dawiso Integration Runtime (DIR) is a small but powerful utility that allows metadata ingestion to run from inside your own infrastructure. You can think of it as Dawiso’s way of reaching in without actually stepping into your environment.
DIR connects to your data sources using standard protocols and drivers, ODBC for databases like SQL Server or Snowflake, and REST APIs for tools like Tableau or Power BI. Once connected, it extracts metadata, saves it to structured JSON files, compresses those files using Gzip, and then sends them securely to your Dawiso cloud environment over HTTPS.
Before any data is sent, you can inspect the files to confirm exactly what will be transferred. This transparency is one of the key reasons many customers choose DIR. It gives you full visibility into what’s being shared and when.
DIR can run on both Windows and Linux, and it doesn’t require much in terms of hardware. A machine with 2 vCPUs and 4 GB of RAM is enough for typical use cases. You just need some disk space for temporary files and an internet connection to Dawiso’s ingestion API. If you don’t have .NET 8 installed, there’s a self-contained version of DIR you can use without admin rights.
Additional features: write-back and export
Dawiso is just starting by collecting metadata. It also supports writing metadata back into external tools. For example, if you document a field in Dawiso (say, explaining what “interest margin” means), that description can be pushed back into Tableau so users there benefit from the same consistent definition. This write-back is handled using the same REST API principles.
For teams that prefer working with Excel, Dawiso supports both exporting and importing metadata in spreadsheet form. You can export metadata to a spreadsheet, update it manually, and import it back into the platform. This is useful in cases where direct database access isn’t possible, or when you want to distribute metadata templates to business users for input.
Summary
Dawiso’s data ingestion architecture is designed for maximum adaptability, whether you’re operating in a fully cloud-native environment or behind multiple layers of on-premise security. With flexible push and pull ingestion patterns, support for shared and private connections, and the DIR module for secure local scanning, Dawiso gives data teams powerful tools to bring metadata into one unified catalog securely, efficiently, and on their own terms.


